
آزمون تصادفی بودن دادهها (Run Tests) یکی از شرایط زیربنایی جهت تعمیم نتایج نمونه به جامعه براساس اصل «تصادفی بودن دادهها» است. با استفاده از این آزمون مشخص میشود تا چه حد دنبالهای از اعداد به صورت تصادفی گردآوری شدهاند. در مقاله حاضر «آزمون تصادفی بودن دادهها» مفهومسازی و تعریف خواهد شد و کاربردهای آن بیان میشود.
آزمون تصادفی بودن دادهها چیست؟
آزمون تصادفی بودن دادهها یکی از ابزارهای بنیادی در آمار کاربردی مدیریت است که به کمک آن میتوان تشخیص داد آیا دادههای یک فرایند، سیستم یا پرسشنامه، واقعاً «تصادفی» و مستقل از هم هستند یا اینکه یک الگو یا روند پنهان در پس آنها وجود دارد.
آزمونهای تصادفیبودن (آزمون دنبالهها) برای بررسی نظم یا الگوی پنهان در دادهها بهکار میروند. این آزمونها مشخص میکنند که آیا دادههای شما بهصورت کاملاً تصادفی رخ دادهاند یا یک الگو، روند، وابستگی یا خوشهبندی در پسِ آنها وجود دارد.
این موضوع با آزمون Run-Test در نرمافزار SPSS انجام میشود. برای نمونه در نمونهگیریهای تصادفی از مشتریان یک فروشگاه این آزمون بخوبی میتواند برای تایید ادعای تصادفی بودن دادهها مورد استفاده قرار گیرد. بیان فرضیههای آماری به صورت زیر است:
فرض صفر : توزیع دادهها به صورت تصادفی است.
فرض بدیل : توزیع دادهها به صورت تصادفی نیست.
اگر این آزمون در سطح خطای ۵% صورت گیرد چنانچه مقدار معناداری آزمون از سطح خطا بزرگتر باشد تصادفی بودن دادهها تایید میشود.
تحلیل آماری پایاننامه و رساله دکتری
راهنمای تحلیل آماری پایاننامه و رساله دکتری مدیریت:
- تحلیل دادههای آماری با روشهای کمی
- تحلیل و کدگذاری مصاحبه با روشهای کیفی
- تحلیل آماری پایاننامه کارشناسی ارشد
- تجزیهوتحلیل روشهای آمیخته رساله دکتری

مسیر آزمون تصادفی بودن دادهها در SPSS
برای آزمون تصادفی بودن دادهها از منوی Analyze وارد مسیر زیر شوید
Analyze/Nonparametric Test/Runs…
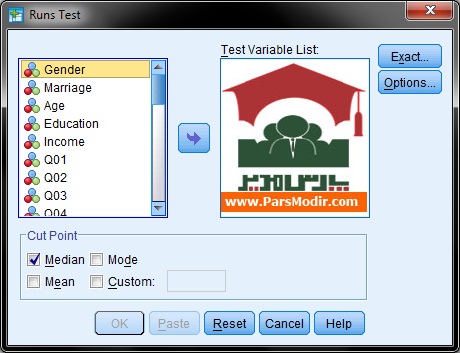
بررسی تصادفی بودن داده ها
میتوانید Cut Point را روی میانگین تنظیم کنید.
متغیرهای مورد نظر را هم میتوانید همزمان به کادر Test Variable List منتقل کنید.
ملاک تصمیمگیری Asymp. Sig. (2-tailed) میباشد. اگر این مقدار از سطح خطا بزرگتر باشد، دادهها تصادفی هستند. مطمئن باشید در این حالت آماره Z از ۱.۹۶ کوچکتر خواهد بود.
تصادفی بودن و نرمال بودن دادهها
آزمون تصادفی بودن و آزمون نرمال بودن داده ها، دو مفهوم کاملاً متفاوت را بررسی میکنند و ماهیت آنها مستقل از یکدیگر است.
آزمون نرمال بودن توزیع دادهها را بررسی میکند؛ یعنی میسنجد شکل پراکندگی دادهها آیا شبیه زنگوله نرمال هست یا نه. روشهایی مثل شاپیرو–ویلک برای همین کار طراحی شدهاند.
اما آزمون تصادفی بودن بر «ترتیب دادهها» تمرکز دارد. اینکه مشاهدات چگونه کنار هم قرار گرفتهاند و آیا نشانهای از وابستگی، الگو، روند یا خوشهبندی در آنها دیده میشود. این آزمون به شکل توزیع اهمیت نمیدهد، بلکه فقط بررسی میکند دادهها مستقل از هم رخ دادهاند یا خیر.
سخن پایانی
در بیشتر روشهای آماری که برمبنای «نمونهگیری» (Sample) شکل گرفتهاند، فرض بر تصادفی بودن نمونه و مشاهدات است. در نتیجه اطمینان از تصادفی بودن نمونهها از اهمیت زیادی برخوردار است. حتی در مباحث مربوط به رگرسیون نیز باید تصادفی بودن باقیماندهها مورد بررسی قرار گرفته تا صحت مدل ایجاد شده مورد تایید قرار گیرد. برای بررسی تصادفی بودن دادههایی که بخصوص در طی زمان جمعآوری شدهاند، میتوان از روشهای ترسیمی و رسم نمودارهای کنترلی به مانند مباحث کنترل کیفیت آماری نیز استفاده کرد. ولی در اینجا هدف استفاده از تکنیک آزمون فرض آماری است که بتواند با توجه به روند و توالی مشاهدات، تصادفی بودن آنها را تایید کند. استفاده از این روش کاربرد زیادی در تحلیل آماری مدیریت و علوم اجتماعی ندارد با این وجود آگاهی از آن نیز خالی از لطف نمیباشد.
منبع: حبیبی، آرش؛ سرآبادانی، مونا. (۱۴۰۱). آموزش کاربردی SPSS. تهران: ناروندانش.



