
دادههای گمشده (Missing data) شامل خانههایی در یک یک فایل داده است که مقدار یا ارزشی برای متغیر مورد بررسی برای آن منظور نشده است. این مسئله میتواند نتایج پژوهش را به شدت دستخوش تغییر کند بنابراین باید مورد توجه پژوهشگران قرار گیرد. نظر به اهمیت موضوع در این آموزش شیوه برخورد با دادههای گمشده تشریح خواهد شد.
تعریف داده گمشده
داده گمشده به حالتی گفته میشود که مقدار مورد انتظار برای یک متغیر خاص در یک مشاهده (پاسخنامه، فرد یا ردیف داده) ثبت نشده یا در دسترس نیست. این فقدان ممکن است ناشی از موارد زیر باشد:
- عدم پاسخدهی فرد
- خطای ثبت داده
- حذف ناخواسته در فرایند ورود
- حذف ناخواسته در انتقال داده
دادههای گمشده نباید با دادههای پرت (Outlier) اشتباه گرفته شوند. این پدیده زمانی رخ میدهد که پاسخدهنده، بهصورت عمدی یا غیرعمدی، به یک یا چند پرسش پاسخ ندهد. دادههای گمشده بهویژه در پژوهشهای حوزه علوم اجتماعی که بر پایه پرسشنامه و پیمایش اجرا میشوند، رایج هستند.
شیوه برخورد با دادههای گمشده
در پژوهشهای معتبر، یک قاعده سرانگشتی اما پذیرفتهشده این است که: اگر بیش از ۲۰٪ دادههای یک ردیف (مثلاً یک پاسخدهنده) مفقود باشد، آن ردیف حذف شود.
اگر دادههای گمشده اندک باشد میتوان از روشهای زیر استفاده کرد:
- جایگزینی با میانگین فردی (Mean substitution per case)
- جایگزینی با میانگین گویهای (Mean substitution per item)
- جایگزینی با میانگین خوشه یا گروه (در دادههای پیمایشی با خوشهبندی)
جایگزینی با روشهای پیشرفته:
- برآورد چندگانه یا تخمین چندگانه (Multiple Imputation)
- الگوریتم انتظار-بیشینهسازی (Expectation Maximization)
این روش در نرمافزارهایی مثل SPSS، AMOS، R و Mplus در دسترس هستند و دقت بسیار بالایی دارند.
تحلیل آماری پایاننامه و رساله دکتری
راهنمای تحلیل آماری پایاننامه و رساله دکتری مدیریت:
- تحلیل دادههای آماری با روشهای کمی
- تحلیل و کدگذاری مصاحبه با روشهای کیفی
- تحلیل آماری پایاننامه کارشناسی ارشد
- تجزیهوتحلیل روشهای آمیخته رساله دکتری

حذف دادههای گمشده
دادههای ناقص که در آن بیش از ۸۰٪ از گویهها بدون پاسخ باقی ماندهاند، میتوانند باعث تحریف نتایج تحلیلهای آماری بهویژه در تحلیل عاملی یا مدلسازی معادلات ساختاری شوند (آلیسون، 2002).
بر اساس توصیههای روششناسان، هنگامی که مقدار دادهی گمشده در سطح مورد (ردیف یا پاسخدهنده) از آستانه ۲۰٪ فراتر رود، حذف آن مورد قابل توجیه است؛ چرا که برآورد مقدار واقعی پاسخها برای چنین دادههایی دارای خطای بالا و اعتبار پایین خواهد بود (هیر و همکاران، 2020).
چگونه در پژوهش خود گزارش دهیم؟
در گام پیشپردازش دادهها، بررسی اولیه نشان داد که برخی از پاسخدهندگان به بخش قابل توجهی از پرسشنامه پاسخ ندادهاند. بهطور مشخص، چند نمونه مشاهده شد که بهطور کامل فقط به یکی از ردیفها یا بُعدهای پرسشنامه پاسخ داده بودند و سایر بخشها را رها کرده بودند. بنابراین ردیفهایی که به کمتر از ۲۰٪ گویهها پاسخ داده بودند، حذف شدند تا از ورود خطای سیستماتیک به نتایج پژوهش جلوگیری گردد.
شناسایی دادههای گمشده در SPSS
شناسایی دادههای گمشده در نرمافزار SPSS با استفاده از دستور Replace Missing Values از منوی Transform قابل انجام است.
پس از انتخاب کادری مانند زیر نمایان خواهد شد:
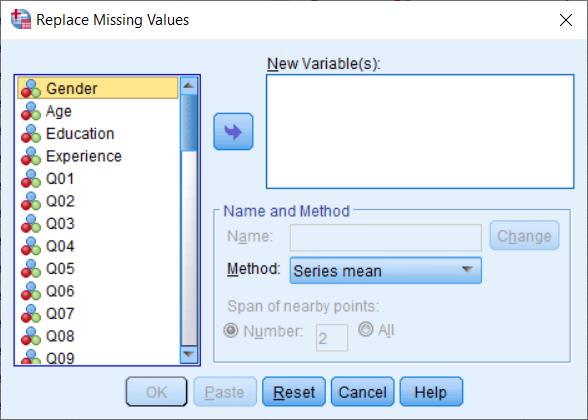
شناسایی دادههای گمشده در SPSS
تمامی متغیرهای مورد نظر خود را به کادر New Variables منتقل کنید.
پیش از این کار از کشوئی Method نوع پوشش نقاط خالی و فاقد داده را انتخاب کنید. موارد زیر در دسترس است:
- گزینه series mean: پرکردن جاهای خالی براساس میانگین دادههای آن فیلد پر میکند.
- گزینه Mean of nearby points: جای خالی را براساس میانگین دادههای اطراف آن خانه خالی پر میکند.
- گزینه Median of nearby points: جای خالی را براساس میانه دادههای اطراف آن خانه خالی پر میکند.
- گزینه Linear interpolation: جاهای خالی را براساس معادلات خطی دادهها پر میکند.
- گزینه Linear trend at point: جاهای خالی را براساس روندنمای خطی دادهها پر میکند.
پیشنهاد میشود برای ستونهای مربوط به متغیرهای طیف لیکرت از گزینه series mean و برای اطلاعات آمار توصیفی و دادههای اسمی و ترتیبی از گزینه Median of nearby points استفاده کنید.
چند نکته کلیدی
استفاده از گزینه Replace Missing Values نکات مربوط به خود را دارد. برای نمونه فرض کنید متغیری مانند Q1 را برای اسکن دادههای گمشده انتخاب کرده باشید در این صورت خود برنامه متغیری با نامی مانند Q1_1 درست میکند. پس از اسکن دادههای گمشده و تکمیل آن براساس پوشش نقاط خالی که انتخاب کردهاید یک فیلد جدید با نام Q1_1 در انتهای فایل داده قبلی ایجاد و نتایج را ذخیره میکند.
اگر میخواهید چنین نشود و اصلاحات در همان فیلد قبلی صورت گیرد (و معمولاً هم چنین است) خودتان نام متغیر را به همان نام قبلی تغییر دهید و دکمه را که اکنون فعال شده است را فشار دهید.
اگر از کشوئی Method یکی از دو گزینه زیر را انتخاب کنید باید در قسمت Number مشخص کنید منظورتان از Nearby (همان دادههای اطراف) چند داده است. همانطور که بیان شد گزینه Mean of nearby points جای خالی را براساس میانگین دادههای اطراف آن خانه خالی پر میکند. گزینه Median of nearby points نیز جای خالی را براساس میانه دادههای اطراف آن خانه خالی پر میکند.
دادههای گمشده در حداقل مربعات جزئی
دادههای گمشده در نرمافزار Smart PLS با نام «ارزشهای گمشده» یا Missing values نمایش داده میشود. اگر فایل دادهای که فراخوانی شده است دارای مقادیر گمشده باشد در زمانی که الگوریتم حداقل مربعات جزئی اجرا میشود یک زبانه جدید به نام ارزشهای گمشده به آن اضافه میشود.
راهکارهای مواجهه با دادههای گمشده در حداقل مربعات جزئی عبارتند از:
- جانهی میانگین [Mean replacement]
- حذف موردی [Casewise Deletion]
- حذف زوجی [Pairwise Deletion]
جانهی (Imputation) در آمار، فرایند جایگزینکردن دادههای گمشده با مقدارهای جایگزین است. جایگزین کردن یک نقطه داده گمشده، بهعنوان «جانهی یکه»، و یک مولفه یک نقطه داده بهعنوان «جانهی موردی» شناخته میشود.
در روش جانهی میانگین، از میانگین سایر دادههای مربوط به آن گویه در فایل داده به جای داده گمشده استفاده میشود. بهدیگر سخن مقادیر خالی هر ستون با میانگین سایر دادههای آن ستون جایگزین میشود. مزیت این روش آن است که حجم نمونه و میانگین دادههای هر ستون ثابت باقی میماند. با این وجود واریانس دادهها تغییر میکند و بر همین اساس ضریب مسیر سازهها نیز تغییر خواهد کرد.
حذف موردی (Casewise Deletion) راهکار دیگری است که نرمافزار Smart PLS برای حذف دادههای گمشده در هر معرف مورد استفاده در مدل را پیشنهاد میدهد. زمانیکه از این روش استفاده میشود دو موضوع نیاز به توجه بیشتری دارند:
نخست اطمینان از اینکه بهصورت سیستماتیک گروه ویژهای از پاسخگویان حذف نشدهاند. برای نمونه پژوهشگران بازاریابی بهصورت متناوب مشاهده میکنند که پاسخدهندگان ثروتمند در پاسخ به پرسشهای پیرامون میزان درآمدشان سر باز میزنند. استفاده از حذف مورد به صورت سیستماتیک، این گروه از پاسخگویان را نادیده میگیرد و بنابراین احتمالا موجب اریبی در نتایج میشود.
دو دیگر آنکه استفاده از این روش میتواند بهصورتی چشمگیر تعداد مشاهدات در مجموعه دادهها را کاهش دهد. بنابراین کنترل دقیق تعداد مشاهدههای مورداستفاده در برآورد مدل نهایی هنگامیکه از این روش استفاده میشود بسیار مهم است.
سخن پایانی
دادههای گمشده همواره یکی از چالشهای مهم در تحلیلهای آماری، بهویژه در مطالعات مبتنی بر پیمایش هستند. اگرچه روشهای پیشرفتهای برای برآورد و جایگزینی این دادهها وجود دارد، اما آنچه اهمیت دارد، انتخاب راهبردی متناسب با هدف پژوهش و ویژگیهای نمونه است. بهرهگیری از میانگین زیرگروههای جمعیتشناختی یا معدل آیتمهای یک سازه، میتواند به حفظ انسجام درونی دادهها و کاهش تحریف در نتایج کمک کند. با وجود تنوع روشهای جایگزینی، در زمینه مدلسازی حداقل مربعات جزئی (PLS) همچنان نیاز به مطالعات بیشتر برای ارزیابی دقت و برازندگی این رویکردها وجود دارد. از این رو، پژوهشگران باید با دقت، آگاهی و شفافیت، روش انتخابی خود برای مدیریت دادههای گمشده را مستند کنند.
فهرست منابع
حبیبی، آرش؛ سرآبادانی، مونا. (۱۴۰۱). آموزش کاربردی SPSS. تهران: نارون.
حبیبی، آرش. (۱۴۰۱). کتاب حداقل مربعات جزئی. تهران: نارون.
Allison, P. D. (2002). Missing Data. Sage Publications.
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2019). Multivariate Data Analysis (8th ed.). Cengage Learning.



