
متغیر تعدیلکننده (Moderator Variable) متغیری است که به صورت مستقیم بر جهت یا میزان رابطه متغیرهای مستقل و وابسته میتواند موثر باشد. در بسیاری از مباحث آمار و کاربرد آن در مدیریت پژوهشگران باید نقش تعدیلگر متغیرها را برآورد نمایند. در این مقاله «متغیر تعدیلکننده» و روشهای برآورد آن در نرمافزار SPSS تشریح خواهد شد.
تعریف متغیر تعدیلکننده
متغیر تعدیلگر متغیری است که رابطه بین دو متغیر دیگر را تحت تاثیر قرار میدهد. اثرات این متغیر قابل مشاهده و اندازهگیری است. به متغیر تعدیل کننده گاهی متغیر مستقل فرعی نیز گویند.
همانطور که در شکل مشخص است اگر متغیر مستقل با X و متغیر وابسته با Y نمایش داده شود آنگاه رابطه بین متغیر مستقل و وابسته را با XY نمایش میدهیم. متغیر تعدیلگر M به صورت مستقیم خود رابطه XY را تحت تاثیر قرار میدهد. متغیر میانجی به صورت غیرمستقیم بر رابطه تاثیر دارد.

مدل نمادین متغیر تعدیلگر (تعدیلکننده)
متغیر تعدیلگر یک متغیر کمی یا کیفی است که جهت و قدرت رابطه متغیر مستقل و وابسته را تحت تاثیر قرار میدهد. برای نمونه متغیر جنسیت در بررسی رابطه روش تدریس و یادگیری دانشآموزان یک متغیر تعدیل کننده است.
مثال مدیریتی: در رابطه میزان «استقلال کاری» و «استرس کارکنان» انتظار میرود هرچه استقلال شغلی بیشتر باشد استرس نیز کمتر شود اما متغیر «رده کاری» این رابطه را تعدیل میکند. برای مثال کارگرانی که تخصص پایینی دارند و در سطوح عملیاتی هستند دوست دارند ناظری کار آنها را کنترل کند. بنابراین رده شغلی، رابطه استقلال و استرس را تعدیل میکند.
تحلیل آماری پایاننامه و رساله دکتری
راهنمای تحلیل آماری پایاننامه و رساله دکتری مدیریت:
- تحلیل دادههای آماری با روشهای کمی
- تحلیل و کدگذاری مصاحبه با روشهای کیفی
- تحلیل آماری پایاننامه کارشناسی ارشد
- تجزیهوتحلیل روشهای آمیخته رساله دکتری

انواع متغیر تعدیلکننده و روش محاسبه آن
بارون و کنی (۱۹۸۶) در مقاله خود چهار حالت گوناگون از وضعیت متغیر مستقل و تعدیلگر را به شرح زیر بررسی کردند:
- حالت اول: متغیر مستقل و تعدیلگر هر دو از نوع طبقهای (اسمی-رتبهای) باشند.
- حالت دوم: متغیر تعدیلگر از نوع طبقهای و متغیر مستقل پیوسته باشد.
- حالت سوم: متغیر تعدیلگر پیوسته و متغیر مستقل از نوع طبقهای باشد.
- حالت چهارم: هر دو متغیر تعدیلگر و مستقل پیوسته باشند.
حالت اول: هر دو متغیر مستقل و تعدیلگر طبقهای (اسمی یا رتبهای) باشند.
در این حالت رابطه بین دو متغیر بهوسیله تحلیل واریانس دوراهه (Two-way ANOVA) بررسی میشود. برای مثال اگر بخواهید نقش جنسیت را در تأثیر سمت سازمانی بر رضایت شغلی ارزیابی کنید، هر سه متغیر ماهیت طبقهای دارند و تحلیل واریانس دوراهه روش مناسب است.
حالت دوم: متغیر مستقل پیوسته و متغیر تعدیلگر طبقهای باشد.
این حالت در پژوهشهای مدیریتی بسیار رایج است. برای نمونه، بررسی نقش جنسیت در رابطه اعتماد و رضایت شغلی در همین گروه قرار میگیرد. در این وضعیت، از رگرسیون خطی با ایجاد متغیر تعامل (Interaction Term) استفاده میشود.
حالت سوم: متغیر مستقل طبقهای و متغیر تعدیلگر پیوسته باشد.
این حالت کمتر در پژوهشهای مدیریتی دیده میشود. هرچند از نظر فنی امکان تحلیل با رگرسیون خطی وجود دارد، اما رویه متداولی نیست و معمولاً پژوهشگران ترجیح میدهند مدل را به شکلی بازتعریف کنند که متغیر مستقل طبقهای کدگذاری دودویی یا چندگانه شده و سپس تعامل با متغیر پیوسته محاسبه شود.
حالت چهارم: هر دو متغیر مستقل و تعدیلگر پیوسته باشند.
در این حالت از رگرسیون خطی با متغیر تعامل استفاده میشود. در تحلیلهای پیشرفتهتر میتوان از رویکرد هایس (Hayes Process) برای محاسبه اثر تعدیلگری و آزمون معناداری شیبها بهره گرفت. این حالت زمانی کاربرد دارد که هر دو مؤلفه از جنس عوامل اصلی (Main Effects) باشند و پژوهشگر بخواهد اثر ترکیبی آنها را بررسی کند.
انواع مقیاس سنجش متغیرهای پژوهش
برای محاسبه متغیر تعدیلگر در SPSS باید با انواع مقیاس اندازهگیری متغیرها آشنا باشید که عبارتند از:
- اسمی (Nominal)
- رتبهای (Ordinal)
- فاصلهای (Interval)
- نسبی (Ratio)
مقیاس اسمی (Nominal Scale): برای دستهبندی دادهها بدون هرگونه ترتیب بهکار میرود و تنها نام یا برچسب گروهها را نشان میدهد. برای مثال «جنسیت پژوهشگران» یا «نوع صنعت» متغیری اسمی است.
مقیاس رتبهای (Ordinal Scale): در این مقیاس میان گروهها ترتیب وجود دارد، اما فاصلهها برابر و قابل اندازهگیری نیست. برای نمونه «رده شغلی کارکنان» یک متغیر رتبهای است.
مقیاس فاصلهای (Interval Scale): فاصله بین مقادیر یکسان و قابل اندازهگیری است، اما صفر واقعی وجود ندارد. برای مثال «نمره رضایت شغلی بر اساس طیف لیکرت» یک متغیر فاصلهای محسوب میشود.
مقیاس نسبی (Ratio Scale): دارای صفر واقعی است و امکان انجام محاسبات دقیق مانند نسبتگیری وجود دارد. برای نمونه «سالهای سابقه خدمت» یا «حجم فروش» متغیر نسبی است.
مثال محاسبه متغیر تعدیلگر در SPSS
در بررسی نقش متغیر تعدیلکننده، حالت دوم یکی از رایجترین موقعیتها است. در بسیاری از پژوهشهای مدیریتی لازم است تأثیر یک متغیر جمعیتشناختی بر رابطه میان دو سازه اصلی مدل ارزیابی شود.
مثال: بررسی نقش تعدیلگر جنسیت در رابطه اعتماد و وفاداری پژوهشگران به پارسمدیر
فرضیه پژوهشی: جنسیت رابطه میان اعتماد و وفاداری را تعدیل میکند.
برای آزمودن فرضیه ی پژوهش از رگرسیون خطی استفاده میشود.
در محیط SPSS چهار متغیر برای انجام این تحلیل باید وارد شود.
جنسیت افراد نمونه، نمره اعتماد و وفاداری افراد و در نهایت متغیر مضروب جنسیت در اعتماد نیز باید محاسبه گردد.
برای برآورد مضروب جنسیت*اعتماد، از سربرگ Transform و گزینه Compute variable استفاده کنید.
متغیر جنسیت را از سمت چپ به کادر Numeric Expression منتقل کنید. با کلیک بر گزینه نماد * جلوی جنسیت علامت ضرب بگذارید.
متغیر اعتماد را به این کادر اضافه کنید و برای متغیر مضروب در قسمت Target Variable یک اسم انتخاب و روی دکمه OK کلیک کنید.
متغیر مضروب مورد نظر در محیط SPSS ساخته خواهد شد.
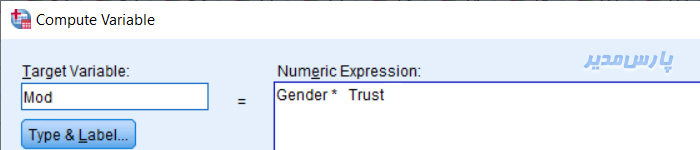
محاسبه متغیر مضروب در SPSS
در این تمرین، متغیری به نام Mod را ایجاد کردیم که حاصل ضرب جنسیت (Gender) در اعتماد (Trust) است.
- از منوی Analyze گزینه Regression فرمان Linear را اجرا کنید.
- متغیر وابسته وفاداری را به کادر Dependent وارد کنید.
- در تکنیک رگرسیون خطی فقط میتوان یک متغیر را به کادر Dependent وارد کنید.
- متغیر مستقل اعتماد را به کادر Independent وارد کنید.
- روی دکمه Next کلیک کنید.
- متغیر مضروب (Mod) را به کادر Independent وارد و دکمه OK کلیک کنید.
نتایج حاصل از رگرسیون با در نظرگیری نقش متغیر تعدیلگر در خروجی زیر نمایش داده خواهد شد.
تفسیر نقش متغیر تعدیلگر در SPSS
اولین خروجی مربوط به جدول Model Summary است.

جدول خلاصه تغییرات مدل رگرسیون
همانگونه که در نخستین جدول خروجی در شکل بالا مشاهده میشود، میزان ضریب تشخیص متغیر وابسته از ۰/۵۰۳ به ۰/۵۱۳ افزایش یافته است.
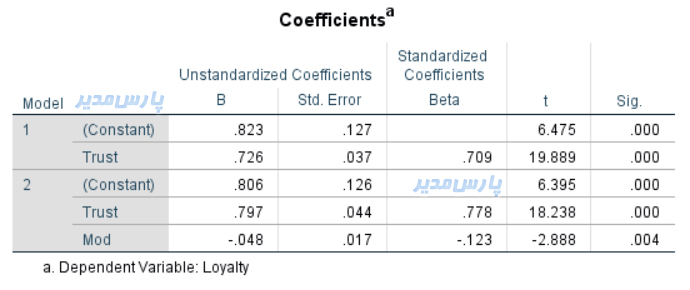
محاسبه ضریب متغیر تعدیلگر
جدول بااهمیت بعدی Coefficients است.
میزان تاثیر اعتماد بر وفاداری در مدل نخست ۰/۷۰۹ و در مدل دوم ۰/۷۷۸ بدست آمده است.
همچنین در مدل شماره دو مشخص شده است که متغیر تعدیلگر جنسیت نقش کاهشی دارد و میزان آن -۰/۱۲۳ بدست آمده است. از آنجا که آماره تی نیز -۲/۸۸۸ بدست آمده است و قدرمطلق آن از مقدار بحرانی ۱/۹۶ بزرگتر است بنابراین نقش تعدیلگری جنسیت معنادار است.
کاربرد آزمون z فیشر در تفسیر نقش متغیر تعدیلگر
آزمون z فیشر زمانی بهکار میرود که پژوهشگر بخواهد قدرت رابطه بین دو متغیر را در دو گروه مستقل مقایسه کند. فرمول این آزمون بهصورت زیر است:
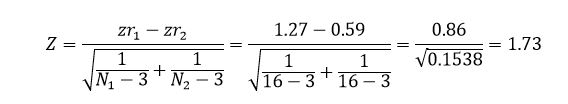
محاسبه میزان تاثیر تعدیلگر با آزمون فیشر
برای مثال بررسی اینکه رابطه اعتماد و وفاداری در مردان قویتر است یا در زنان. ابتدا همبستگی دو گروه محاسبه میشود و سپس این مقادیر با تبدیل فیشر به zr تبدیل میگردند. با استفاده از حجم نمونه هر گروه، آماره z بهدست میآید و بر اساس مقدار بحرانی تصمیمگیری میشود.
در مثال فرضی ما، همبستگی مردان ۰٫۸۵۵ و زنان ۰٫۵۳۰ است که پس از تبدیل به مقادیر ۱٫۲۷ و ۰٫۵۹ تبدیل میشوند. مقدار z برابر با ۱٫۷۳ بهدست آمده و چون از مقدار بحرانی آزمون دوسویه (۱٫۹۶) کوچکتر است، نقش تعدیلگری جنسیت تأیید نمیشود. البته اگر فرضیه از ابتدا یکسویه تدوین شده بود، مقدار z بزرگتر از حد بحرانی یکسویه (۱٫۶۵) بود و میتوانست معنادار تلقی شود.
توجه مهم اینکه جهتدار بودن فرضیه باید پیش از جمعآوری دادهها مشخص شود و پس از مشاهده نتایج نمیتوان آن را تغییر داد.
متغیر تعدیلکننده و رگرسیون سلسلهمراتبی
رگرسیون سلسلهمراتبی (Hierarchical Regression) روشی است که در آن متغیرهای مستقل در چند گام وارد معادله میشوند تا سهم هر مجموعه از متغیرها در تبیین متغیر وابسته مشخص شود. این روش یکی از رویههای رایج برای آزمون اثر تعدیلگر بر اساس چارچوب بارون و کنی است.
در مرحله نخست، متغیر مستقل و متغیر تعدیلگر وارد مدل میشوند. در مرحله دوم، متغیر تعامل یا حاصلضرب دو متغیر (X×M) افزوده میشود. اگر اضافه شدن متغیر تعامل بهطور معنادار واریانس تبیینشده مدل را افزایش دهد، اثر تعدیلگری تأیید میشود.
در پرسشنامه طیف لیکرت، هر سازه از چند گویه تشکیل شده است و برای ورود به رگرسیون باید به یک شاخص قابل مشاهده تبدیل شود. معمولترین روش، محاسبه میانگین گویههای مربوط به هر سازه است تا برای تحلیل بهعنوان یک متغیر پیوسته قابل استفاده باشد. رگرسیون سلسلهمراتبی زمانی کاربرد دارد که پژوهشگر بخواهد نقش تعدیلگری یک متغیر جمعیتشناختی یا یک سازه روانسنجی را بر رابطه میان دو متغیر اصلی آزمون کند.
سخن پایانی
در جمعبندی میتوان گفت متغیر تعدیلگر یکی از عناصر کلیدی در تحلیلهای پیشرفته است که پژوهشگر را قادر میسازد روابط پیچیدهتر و واقعیتری میان متغیرها شناسایی کند. وجود یک تعدیلگر نشان میدهد اثر متغیر مستقل بر متغیر وابسته برای همه افراد، گروهها یا شرایط یکسان نیست و بسته به ویژگیهای تعدیلگر میتواند تقویت، تضعیف یا حتی معکوس شود. استفاده صحیح از تحلیل تعدیلگری —چه با دادههای کمی و چه کیفی— به پژوهشگر کمک میکند تبیین دقیقتری از رفتار پدیدهها ارائه دهد و به درک عمیقتری از تفاوتها و شرایط زمینهای برسد. به همین دلیل شناخت متغیر تعدیلگر، تشخیص نوع آن و نحوه محاسبهاش در نرمافزارهایی مانند SPSS از پیشنیازهای مهم هر پژوهش علمی معتبر است.
منبع: حبیبی، آرش؛ سرآبادانی، مونا. (1401). آموزش کاربردی SPSS. تهران: ناروندانش.
سوالات متداول
متغیر تعدیلگر متغیری است که شدت یا جهت رابطه بین متغیر مستقل و وابسته را تغییر میدهد؛ یعنی اثر X بر Y برای همه افراد یکسان نیست و بسته به سطح تعدیلگر متفاوت میشود. در مقابل، میانجی متغیری است که فرایند انتقال اثر را توضیح میدهد و نشان میدهد X چگونه و از چه طریقی بر Y اثر میگذارد. بنابراین تعدیلگر رابطه را تغییر میدهد، اما میانجی آن را تبیین میکند.
بله، در هر دو رویکرد کوواریانسمحور (AMOS) و حداقل مربعات جزئی (PLS) امکان تحلیل تعدیلگری وجود دارد. معمولترین روش ساختن متغیر تعامل میان متغیر مستقل و تعدیلگر و وارد کردن آن در مدل است. در PLS این کار سادهتر انجام میشود؛ اما در AMOS نیاز به تکنیکهایی مانند روش محصول شاخصها (Product Indicator) یا روش دو مرحلهای وجود دارد.
متغیر تعامل حاصلضرب متغیر مستقل در تعدیلگر است و نشان میدهد آیا اثر X بر Y در سطوح مختلف M متفاوت است یا خیر. این متغیر در مدل دوم رگرسیون وارد میشود و اگر بهطور معنادار R² مدل را افزایش دهد، نقش تعدیلگر تأیید میشود. تفسیر ضریب تعامل همیشه وابسته به نوع مقیاس متغیرها و نحوه کدگذاری آنهاست.
در رگرسیون سلسلهمراتبی ابتدا متغیرهای اصلی وارد مدل میشوند و سپس متغیر تعامل افزوده میشود. اگر ورود متغیر تعامل باعث افزایش معنادار R² یا معناداری ضریب تعامل شود، اثر تعدیلگری وجود دارد. همچنین لازم است تغییرات مدل با آزمونهای تکمیلی مثل F-change بررسی شود تا از معناداری واقعی تعدیلگر اطمینان حاصل گردد.



