
فاصله ماهالانوبیس (Mahalanobis distance) فاصله یک داده ویژه از توزیع دادهها در میان دادههای گردآوری شده یک نمونه آماری است. روش آماری برآورد این فاصله دشوار است و برای پژوهشگران مدیریت و علوم اجتماعی کاربرد چندانی ندارد. بویژه آنکه زمانی که حجم دادهها زیاد باشد امکان برآورد دستی بسیار دشوارتر نیز خواهد شد. بنابراین در این آموش کوشش بر آن است تا به بیان نقش و شیوه برآورد آن در نرمافزار SPSS پرداخته شود.
تعریف فاصله ماهالانوبیس
فاصله ماهالانوبیس شاخصی آماری برای سنجش میزان فاصله یک مشاهده از مرکز یک توزیع چندمتغیره است. با این تفاوت که همزمان واریانس هر متغیر و همبستگی میان متغیرها را نیز در نظر میگیرد. به همین دلیل، برخلاف فاصله اقلیدسی، برای دادههای چندبعدی و همبسته کاملاً مناسب است.
فاصله ماهالانوبیس معیاری استاندارد برای شناسایی دادههای پرت چندمتغیره (Multivariate Outliers) است و در تحلیل رگرسیون، مدلهای ساختاری، خوشهبندی و تشخیص الگو کاربرد گسترده دارد.
این شاخص را پراسانتا چاندرا ماهالانوبیس، آماردان هندی، در سال ۱۹۳۶ معرفی کرد. او بنیانگذار «مؤسسه آمار هند» بود و برای نخستینبار نشان داد که در دادههای چندبعدی نمیتوان از فاصله ساده اقلیدسی استفاده کرد؛ زیرا نادیده گرفتن همبستگیها موجب برداشتهای اشتباه میشود. این روش یکی از تأثیرگذارترین ابزارهای آماری قرن بیستم محسوب میشود.
برآورد فاصله ماهالانوبیس در نرمافزار SPSS
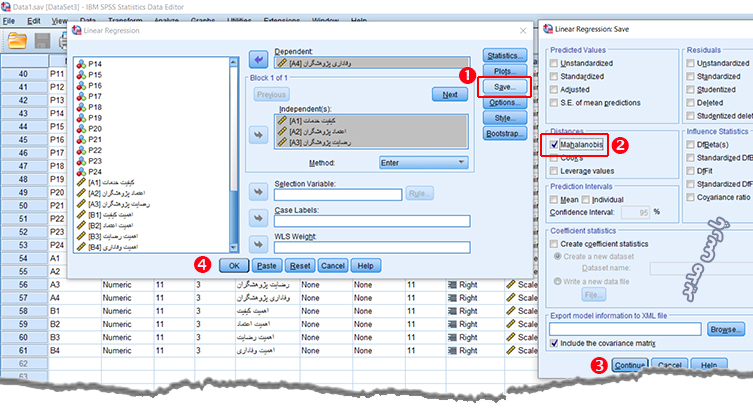
برای شروع آزمون رگرسیون خطی را اجرا کنید.
از منوی Analyze گزینه Regression فرمان Linear را اجرا کنید تا دیالوگ رگرسیون خطی پدیدار شود.
متغیرهای مستقل و وابسته را به کادرهای مربوط وارد کنید.
روی دکمه Save مانند شکل کلیک کنید.
در دیالوگ جدید گزینه Mahalanobis را تیک بزنید.
در پایان دکمه Continue و پس از آن OK را کلیک کنید.
شناسایی دادههای پرت با فاصله ماهالانوبیس
در خروجی رگرسیون جدولی به Residuals Statistics اضافه خواهد شد. در این جدول Mahalanobis را پیدا کنید چنانچه بیشینه (ماکسیموم) بالای آن از تعداد سازههای پیشبین بیشتر باشد نشان از وجود دادههای پرت میباشد.
اگر به فایل داده برگردید مشاهده خواهید کرد یک فیلد جدید بهنام MAH_1 اضافه شده است. اکنون باید معناداری فاصلههای برآورده شده را آزمون کنید. برای این کار از تابع CDF.CHISQ استفاده میشود. این تابع دارای دو آرگومان است. آرگومان اول نام متغیر موردنظر و آرگومان دوم تعداد متغیرهای پیشبین است. برای نمونه اگر سه سازه پیشبین دارید از تابع زیر استفاده کنید:
۱ – CDF.CHISQ(MAH_1,3)
از منوی Transform و سپس Compute Variable کلیک کنید. در دیالوگی که باز میشود تابع بالا را وارد کنید و نامی برای سازهای که میخواهید مقدار معناداری در آن درج شود انتخاب کنید. با کلیک روی دکمه OK یک فیلد جدید دربرگیرنده مقادیر معناداری اضافه خواهد شد.
هر رکوردی که معناداری آن کمتر از سطح خطا باشد بهعنوان داده پرت شناسایی میشود. میتوانید روی فیلد معناداری کلیک راست کنید و گزینه Ascending را انتخاب کنید تا دادهها براساس مقادیر از کوچک به بزرگ مرتب شود. به این ترتیب بهتر میتوان دادههای پرت را شناسایی کرد.
شیوه تفسیر
برای برآورد آن نخست باید از منو Analyze گزینه Regression را انتخاب کنید. از بخش باز شده گزینه Linear را انتخاب کنید.
- متغیر وابسته و متغیرهای پیش بین را وارد تحلیل کنید.
- وارد بخش Save شوید و تیک Mahalanobis را انتخاب کنید.
- در پایان گزینه ok را بزنید تا خروجیها نمایش داده شود.
- در خروجیهای نرم افزار باید فاصله ماهالانوبیس را پیدا کنید.
از ماکسیموم این فاصله میتوانید مقدار بحرانی آن را مشخص نمایید. پس از دیدن مقدار ماکسیموم باید به جدول زیر مراجعه نمایید. بر اساس تعداد متغیرهای پیش بین تحلیل، مشخص شده که مقدار بحرانی ماهالانوبیس چند است. اگر عدد ماکسیموم خروجی، بزرگ تر از مقدار بحرانی بود، یعنی این که ما مقادیر پرت مشکل ساز داریم.
در گام پایانی باید به دادههای اصلی مراجعه نمایید. نرمافزار ستون تازهای بهنام MAH ایجاد کرده است. این مقادیر را از بزرگ به کوچک مرتب کنید و کیس هایی که مقدار ماهالانوبیس آنها بالا تر از مقدار بحرانی بوده را از تحلیل خود حذف نمایید.
سخن پایانی
فاصله ماهالانوبیس یکی از ابزارهای کلیدی در تحلیل دادههای چندمتغیره است؛ شاخصی که با درنظرگرفتن واریانس و همبستگی میان متغیرها، تصویری دقیقتر از فاصله و ناهنجاری در دادهها ارائه میدهد. این معیار امکان شناسایی پرتهای پنهانی را فراهم میکند که با روشهای سادهتر قابل تشخیص نیستند و به پژوهشگر کمک میکند ساختار واقعی دادهها را بهتر درک کرده و مدلهای معتبرتری برآورد کند. استفاده آگاهانه از این فاصله، گامی مهم در اطمینان از کیفیت داده و صحت تحلیلهای آماری است.
Mahalanobis, P. C. (2018). On the generalized distance in statistics. Sankhyā: The Indian Journal of Statistics, Series A (2008-), 80, S1-S7.



