
آزمون نرمال بودن دادهها (Normality test) روشی آماری است که بررسی میکند دادهها از الگوی توزیع نرمال پیروی میکنند یا نه. پیش از انتخاب هر گونه آزمون آماری باید نرمال بودن توزیع دادهها بررسی شود. بنابراین اهمیت این مسئله کاملا روشن است؛ نظر به اهمیت موضوع در این مقاله «آزمون نرمال بودن دادهها» مفهومسازی و روشهای گوناگون آن آموزش داده خواهد شد.
تعریف نرمال بودن و توزیع نرمال
در آمار استنباطی انتخاب انواع آزمونهای آمار پارامتریک و ناپارامتریک به توزیع دادهها بستگی دارد. اگر توزیع دادهها نرمال باشد در اینصورت از روشهای پارامتریک استفاده میشود و اگر نرمال نباشد نباید از روشهای پارامتریک استفاده شود. آزمونهای ناپارامتریک ربطی به توزیع دادهها ندارد.
آزمون نرمالبودن روشی آماری است که تعیین میکند آیا دادههای گردآوریشده از توزیع طبیعی (نرمال) پیروی میکنند یا خیر.
نرمالبودن به این معناست که دادهها الگوی توزیع زنگولهای شکل دارند؛ یعنی بیشترین فراوانی در میانه، کاهش تدریجی در دو سوی میانگین، و تقارن نسبتاً کامل. آزمونهای نرمالبودن برای سنجش این موضوع طراحی میشوند و بهطور کمی مشخص میکنند که دادهها تا چه حد با توزیع نرمال سازگار هستند.
توزیع نرمال (Normal distribution) الگویی آماری است که در آن دادهها بهصورت متقارن پیرامون میانگین پخش میشوند و بیشترین فراوانی در مرکز قرار دارد و هرچه از میانگین دورتر شویم احتمال وقوع کمتر میشود.
انواع آزمونهای نرمالبودن دادهها
۱) شاپیرو–ویلک
یکی از قویترین آزمونها برای حجم نمونههای کوچک و متوسط؛ حساسیت بالا به چولگی و کشیدگی.
۲) کولموگروف–اسمیرنوف (KS)
مقایسهٔ توزیع تجربی دادهها با توزیع نرمال نظری؛ بیشتر برای نمونههای بزرگ مناسب.
۳) آندرسون–دارلینگ
نسخهٔ تقویتشدهٔ KS که به دمهای توزیع حساسیت بیشتری دارد.
۴) لیللیفورس
نسخهٔ اصلاحشدهٔ KS وقتی میانگین و واریانس از خود دادهها برآورد شده باشند.
۵) جارک–برا (JB)
مبتنی بر چولگی و کشیدگی؛ ساده، سریع، و مناسب برای تحلیلهای اقتصادی.
در مجموع، سنجش نرمالبودن دادهها گامی ضروری در انتخاب روشهای آماری مناسب است و از بروز خطا در تحلیل جلوگیری میکند. بهکارگیری درست آزمونهای نرمالبودن کمک میکند تا پژوهشگر تصویر دقیقتری از رفتار توزیعی دادهها به دست آورد و براساس آن تصمیمگیری آماری معتبر انجام دهد.
تحلیل آماری پایاننامه و رساله دکتری
راهنمای تحلیل آماری پایاننامه و رساله دکتری مدیریت:
- تحلیل دادههای آماری با روشهای کمی
- تحلیل و کدگذاری مصاحبه با روشهای کیفی
- تحلیل آماری پایاننامه کارشناسی ارشد
- تجزیهوتحلیل روشهای آمیخته رساله دکتری

کاربرد چولگی و کشیدگی در آزمون نرمال بودن دادهها
بررسی چولگی و کشیدگی یکی از بهترین روشها برای ارزیابی نرمالبودن دادههای لیکرت و پرسشنامه است.
چولگی (Skewness) میزان تقارن یا نامتقارن بودن توزیع دادهها را نشان میدهد؛ در یک توزیع کاملاً متقارن مقدار چولگی صفر است. چولگی مثبت به معنای کشیدهشدن توزیع به سمت مقادیر بزرگتر و چولگی منفی نشاندهنده کشیدگی به سمت مقادیر کوچکتر است.
کشیدگی (Kurtosis) بیانگر ارتفاع قله توزیع و میزان تجمع دادهها در نقطه مرکزی است. مقدار کشیدگی در توزیع نرمال برابر ۳ (یا در تعریف استانداردشده صفر) است. کشیدگی مثبت نشان میدهد قله توزیع بلندتر از نرمال است و کشیدگی منفی حاکی از کوتاهتر بودن قله و پراکندگی بیشتر دادههاست؛ مانند توزیع t که نسبت به نرمال پراکندگی بیشتری دارد و نمودار آن ارتفاع کمتری در مرکز نشان میدهد.
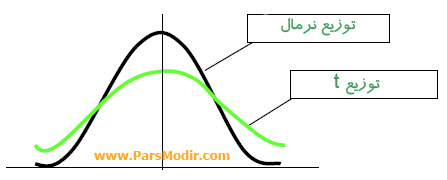
بررسی کشیدگی توزیع نرمال
در حالت کلی چنانچه نسبت چولگی و کشیدگی به خطای استاندارد در بازه (۲، ۲-) باشد دادهها از توزیع نرمال برخوردار هستند.
فرمان زیر را در SPSS اجرا کنید:
Analyze/Descriptive Statistics/Descriptive
در کادر باز شده متغیرهایی که میخواهید چولگی و کشیدگی آن را آزمون کنید را به کادر سفید انتقال دهید. سپس روی کلید options کلیک کنید و در کادر جدید گزینههای Skewness و Kurtosis را فعال کنید. برای مثال به مقادیر جدول زیر دقت کنید:
| Skewness | Kurtosis | |||
| Statistic | Std. Error | Statistic | Std. Error | |
| D1 | ۰.۱۴۶ | ۰.۲۸۷ | ۰.۷۸۴ | ۰.۵۶۶ |
| D2 | -۰.۱۰۹ | ۰.۲۸۷ | -۰.۹۹۴ | ۰.۵۶۶ |
برای متغیر D1 مقدار نسبت چولگی به خطای استاندارد ۰/۵۰۹ و نسبت کورتوسیس ۱/۳۸۵ بدست میآید که در بازه (۲، ۲-) قرار دارد. بنابراین میتوان گفت متغیر D1 نرمال بوده و توزیع آن متقارن است. برای متغیر D2 مقدار نسبت چولگی به خطای استاندارد ۰/۳۸۰ و نسبت کورتوسیس ۱/۷۵۶ بدست میآید که در بازه (۲، ۲-) قرار دارد. بنابراین میتوان گفت توزیع دادههای متغیر D2 نیز نرمال است.
رسم نمودار هیستوگرام برای آزمون نرمال بودن دادهها
ترسیم نمودار هیستوگرام از روشهای آزمون نرمال بودن دادهها است. با استفاده از نرمافزار SPSS به سادگی میتوان نمودار هیستوگرام با نمایش منحنی نرمال را ترسیم کرد. فرمان زیر را در SPSS اجرا کنید:
Analyze/ Descriptive Statistics/ Frequencies
در کادر باز شده متغیرهایی که میخواهید منحنی نرمال را برای آن ترسیم کنید به کادر سفید انتقال دهید. سپس روی کلید Charts کلیک کنید و در کادر جدید گزینههای Histograms و with normal curve را فعال کنید. منحنی نرمال و نمودار هسیتوگرام به نمایش در خواهد آمد.
آزمون کولموگروف-اسمیرنوف
علاوه بر بررسی عادی یا نرمال بودن کشیدگی و یا چولگی توزیع دادهها، از آزمون شاپیرو-ویلک یا آزمون کولموگروف-اسمیرنوف استفاده میشود برای آزمون نرمال بودن دادهها استفاده میشود.
هنگام بررسی نرمال بودن دادهها ما فرض صفر مبتنی بر اینکه توزیع دادهها نرمال است را در سطح خطای ۵% تست میکنیم. بنابراین اگر آماره آزمون بزرگتر مساوی ۰.۰۵ بدست آید، در این صورت دلیلی برای رد فرض صفر مبتنی بر اینکه داده نرمال است، وجود نخواهد داشت. به عبارت دیگر توزیع دادهها نرمال خواهد بود. برای آزمون نرمالیته فرضهای آماری به صورت زیر تنظیم میشود:
H0 : توزیع دادههای مربوط به هر یک از متغیرها نرمال است
H1 : توزیع دادههای مربوط به هر یک از متغیرها نرمال نیست
جهت انجام این دو آزمون فرمان زیر را اجرا کنید:
Analyze/Descriptive Statistics/Explore
در کادر باز شده متغیرهای موردنظر را وارد لیست Dependent list کنید و سایر جاها را خالی بگذارید. سپس روی دکمه plots کلیک کرده و در کادر جدید گزینه Normality plots with tests را تیک دار کنید.
با این عمل خروجی شامل جدولی تحت عنوان Tests of Normality است که به شما دو مقدار سطح معناداری را برای هر کدام از متغیرها به طور مجزا میدهد. این مقادیر در تشخیص نرمال بودن دادهها تعیین کننده است. چنانچه سطح معناداری در آزمون Shapiro-Wilk یا آزمون کولموگروف-اسمیرنوف که در این جدول با sig. نمایش داده میشود بیشتر از ۰.۰۵ باشد میتوان دادهها را با اطمینان بالایی نرمال فرض کرد. در غیر این صورت نمیتوان گفت که دادهها توزیعشان نرمال است.
برای درک بیشتر آزمون نرمال بودن دادهها پیشنهاد میشود آزمون تصادفی بودن داده ها را مطالعه کنید.
آزمون شاپیرو–ویلک
آزمون شاپیرو–ویلک یکی از معتبرترین روشها برای بررسی نرمال بودن دادهها است و بهویژه زمانی که حجم نمونه کوچک یا متوسط باشد کاربرد بالایی دارد. این آزمون با مقایسه الگوی واقعی دادهها با الگوی مورد انتظار در یک توزیع نرمال، میزان انحراف دادهها از نرمال بودن را اندازهگیری میکند. دقت بالای این آزمون در تشخیص چولگی و کشیدگی دادهها باعث شده است که در تحلیل پرسشنامهها، مقیاسهای لیکرت و دادههای رفتاری بیشتر از سایر آزمونها توصیه شود.
نوشتن فرضیه آزمون:
- فرض صفر (H0): دادهها از توزیع نرمال پیروی میکنند
- فرض جایگزین (H1): دادهها از توزیع نرمال پیروی نمیکنند
جمعبندی تصمیمگیری:
- اگر مقدار p-value بزرگتر از ۰٫۰۵ باشد → فرض صفر پذیرفته میشود و دادهها نرمال هستند
اگر مقدار p-value کوچکتر یا مساوی ۰٫۰۵ باشد → فرض صفر رد میشود و دادهها نرمال نیستند
این شیوه، یک راهنمای ساده و علمی برای گزارش نتایج آزمون شاپیرو–ویلک در مقالات و پژوهشهای آماری فراهم میکند.
ملاک آزمون نرمال بودن دادهها چیست؟
وقتی پژوهشگران از برای گردآوری دادهها استفاده میکنند با یک مشکل بزرگ مواجه هستند. برای استفاده از آزمونهای پارامتریک مانند همبستگی پیرسون، رگرسیون، مدل ساختاری و آزمون تی، توزیع دادهها باید نرمال باشد. بهطور مرسوم برای بررسی نرمال بودن از آزمون کولموگروف-اسمیرنوف استفاده میشود. اما نتیجه همیشه ناامید کننده است. نتایج این آزمون نشان میدهد دادهها نرمال نیست. در پاسخ باید گفت استفاده از این آزمون برای دادههای آماری کوچک (کمتر از ۳۰ داده) مناسب است. دوم اینکه استفاده از این آزمون برای دادههای طیف لیکرت مورد تردید است. توصیه شده است از آزمون KS برای پرسشنامههای طیف لیکرت استفاده نشود.
پرسش دوم این است که نتایج آزمون چولگی و کشیدگی دادهها با نتایج آزمون KS همخوانی ندارد. یکی نشان میدهد دادهها نرمال است و یکی خلاف این ادعا را نشان میدهد. تکلیف چیست؟ پاسخ بسیار ساده است. هرگز از آزمون کولموگروف-اسمیرنوف برای بررسی نرمال بودن دادهها استفاده نکنید. براساس کتاب آمار کاربردی مدیریت نوشته کلر (۲۰۱۵) و لوین (۲۰۱۱) بهتر است چولگی و کشیدگی دادهها بررسی شود. همچنین آزمون شاپیرو-ولیک نیز برای دادههای طیف لیکرت مناسب نیست.
بررسی نرمال بودن دادههای پرسشنامه طیف لیکرت
دادههای طیف لیکرت معمولاً ترتیبی (Ordinal) هستند و پیشفرض نرمال بودن برای آنها ضعیف است.
آزمون کولموگروف–اسمیرنوف (K–S) برای دادههای لیکرتی یا حجم نمونههای کوچک (کمتر از ۳۰) مناسب نیست؛ زیرا به حجم نمونه حساس است و اغلب نتیجه «غیرنرمال بودن» میدهد.
آزمون شاپیرو–ولیک نیز برای دادههای ترتیبی توصیه نمیشود.
روش مناسبتر برای ارزیابی نرمال بودن دادهها:
بررسی چولگی (Skewness) و کشیدگی (Kurtosis)؛ اگر نسبت مقادیر هر دو بین ±۲ باشند، دادهها را میتوان تقریباً نرمال دانست.
استفاده از نمودارهای Histogram و Q–Q Plot برای ارزیابی بصری توزیع دادهها.
در پرسشنامه طیف لیکرت و پژوهشهای مدیریت و علوم انسانی، در صورت نرمالبودن تقریبی، استفاده از آزمونهای پارامتریک (پیرسون، تی، رگرسیون) قابل قبول است. برای دادههای لیکرتی، از آزمونهای آماری نرمال بودن (K–S و شاپیرو–ولیک) استفاده نکنید. شاخصهای چولگی و کشیدگی و بررسی بصری بهترین معیارهای تصمیمگیری برای نرمال بودن دادهها هستند (کلر، 2015؛ لوین، 2011).
سخن پایانی
نرمال بودن دادهها یکی از پیششرطهای کلیدی در تحلیلهای آماری است، اما نباید آن را صرفاً یک آزمون عددی دانست. هدف از بررسی نرمال بودن، درک رفتار واقعی دادههاست، نه اتکا به خروجی یک آزمون. پژوهشگر آگاه باید بداند هر روش آماری در چه شرایطی معنا دارد و چگونه ماهیت مقیاس اندازهگیری (مانند طیف لیکرت) بر انتخاب آزمون تأثیر میگذارد. بنابراین، سنجش نرمال بودن باید ترکیبی از دانش نظری، شاخصهای توصیفی و قضاوت تحلیلی باشد.
در نهایت، مهم آن است که پژوهشگر از دادهها «درک آماری» پیدا کند، نه صرفاً «نتیجه آماری».
فهرست منابع
حبیبی، آرش؛ سرآبادانی، مونا. (1401). آموزش کاربردی SPSS. تهران: ناروندانش.
Keller, G. (2015). Statistics for Management and Economics, Abbreviated. Cengage Learning.
Levin, R. I. (2011). Statistics for management. Pearson Education India.
سوالات متداول
بهلحاظ نظری خیر، چون لیکرت مقیاسی ترتیبی است، اما وقتی پاسخها در سطح گروهی میانگینگیری شوند، تقریب نرمال حاصل میشود و میتوان با احتیاط از آزمونهای پارامتریک استفاده کرد.
نباید بلافاصله نتیجه گرفت که توزیع واقعاً غیرنرمال است. در چنین شرایطی باید به شاخصهای چولگی و کشیدگی مراجعه کرد؛ اگر مقدار آنها در بازهی ±۲ (یا حتی ±۳) باشد، دادهها را میتوان تقریباً نرمال دانست. همچنین بررسی نمودارهای Histogram، Q–Q Plot و Boxplot دید بهتری از شکل واقعی توزیع میدهد. در پژوهشهای علوم انسانی و مدیریت، وقتی چولگی و کشیدگی در حد مجاز است، معمولاً دادهها را «تقریباً نرمال» فرض کرده و از آزمونهای پارامتریک استفاده میکنند؛ زیرا نتایج آنها پایاتر و تفسیرپذیرتر است.
اگر انحراف از نرمالیت کم باشد یا حجم نمونه بزرگ باشد، طبق قضیه حد مرکزی دادهها تقریباً نرمال رفتار میکنند، در غیر این صورت بهتر است از آزمونهای ناپارامتریک استفاده شود.
بله، میتوان برای دادههای نرمال از آزمونهای ناپارامتریک استفاده کرد، اما معمولاً توصیه نمیشود. آزمونهای ناپارامتریک به دلیل وابسته نبودن به فرض نرمالیت، دقت و توان آماری (Power) کمتری نسبت به آزمونهای پارامتریک دارند. بنابراین وقتی دادهها نرمال هستند، استفاده از آزمونهای پارامتریک نتایج دقیقتر، قویتر و تفسیرپذیرتری ارائه میدهد.
بهترین روش ترکیبی از بررسی شاخصهای چولگی و کشیدگی همراه با مشاهده نمودارهای Histogram و Q–Q Plot است تا درک دقیقتری از توزیع دادهها حاصل شود.



