
رگرسیون (Regression) یک روش آماری برای سنجش تاثیرات متغیرها با در نظر گرفتن روابط همزمان آنها بر یکدیگر است. معنای لغوی رگرسیون بازگشت به گذشته است و وجه تسمیه این روش نیز استفاده از دادههای گذشته برای پیشبنی آینده است. در این مقاله روش «رگرسیون»، انواع آن و شیوه اجرا و تفسیر این روش آموزش داده خواهد شد.
تعریف و کاربرد رگرسیون
رگرسیون روشی آماری برای مدلسازی و تحلیل رابطهٔ یک متغیر وابسته با یک یا چند متغیر پیشبین است. هدف آن برآورد مقدار مورد انتظار متغیر وابسته بر اساس تغییرات پیشبینها و سنجش شدت و جهت اثر هر یک از آنهاست. پایه این روش بر کمینهسازی خطا میان مقادیر مشاهدهشده و مقادیر پیشبینیشده است.
رگرسیون ابزاری تحلیلی برای سنجش و پیشبینی است؛ روشی که با تکیه بر دادهها، اثر هر پیشبین را در کنار سایر عوامل آشکار میکند و تصویری ساختاری از مناسبات میان متغیرها ارائه میدهد.
ریشه رگرسیون به کارهای فرانسیس گالتون در اواخر قرن نوزدهم بازمیگردد؛ او مفهوم «بازگشت به میانگین» را در مطالعهٔ قد والدین و فرزندان مطرح کرد. سپس کارل پیرسون این ایدهها را بسط داد و چارچوب ریاضی دقیق رگرسیون خطی را شکل داد.
با گسترش روشهای آماری در قرن بیستم، رگرسیون به خانوادهای بزرگ از مدلها ــ از رگرسیون چندگانه تا لوجستیک، درصدی، غیرخطی و مدلهای تعمیمیافته ــ تبدیل شد. اکنون از این روش در مبانی آمار و کاربرد آن در مدیریت بسیار استفاده میشود.
تحلیل آماری پایاننامه و رساله دکتری
راهنمای تحلیل آماری پایاننامه و رساله دکتری مدیریت:
- تحلیل دادههای آماری با روشهای کمی
- تحلیل و کدگذاری مصاحبه با روشهای کیفی
- تحلیل آماری پایاننامه کارشناسی ارشد
- تجزیهوتحلیل روشهای آمیخته رساله دکتری

انواع روش رگرسیون (Regression)
انواع روشهای رگرسیونی براساس مفروضههای آماری و تعداد متغیرهای وابسته و مستقل قابل دستهبندی است. از نظر منطق زیربنایی آماری میتوان روشهای رگرسیونی خطی را به دو دسته تقسیمبندی کرد:
- رگرسیون خطی ساده (Simple linear regression)
- رگرسیون خطی تعمیمیافته (Generalized linear model)

انواع روش رگرسیون (Regression)
رگرسیون خطی ساده
این رویکرد مبتنی بر کمترین مربعات معمولی (OLS) است. همچنین از این روش برای پیشبینی «یک» متغیر وابسته براساس «یک» یا «چند» متغیر مستقل استفاده میشود. نقطه ضعف این رویکرد عدم امکان استفاده از آن برای پیشبینی همزمان چند متغیر وابسته است.
رگرسیون خطی تعمیمیافته
میتوان از مدل خطی عمومی یا Generalized Linear Model (GLM) برای تحلیل رگرسیونی استفاده کرد. GLM به محققان و تحلیلگران کمک میکند تا روابط پیچیده بین متغیرهای مستقل و وابسته را با دقت بیشتری مدلسازی کنند و پیشبینیهای دقیقی انجام دهند.
رگرسیون چندگانه (Multiple): پیشبینی یک یا چند متغیر وابسته براساس چند متغیر مستقل
رگـرسیون چندگانه تک عاملی (Univariate Multiple Regression) : پیشبینی یک متغیر وابسته براساس چند متغیر مستقل
رگـرسیون چندگانه چند عاملی (Multivariate Multiple Regression): پیشبینی چند متغیر وابسته براساس چند متغیر مستقل
در پژوهشهای رگرسیون هدف پیشبینی یک یا چند متغیر وابسته (ملاک) براساس یک یا چند متغیر مستقل (پیشبین) است. در رگرسیون چندگانه هدف پیدا کردن متغیرهای پیشبینی است که تغییرات متغیر وابسته را چه به تنهائی و چه مشترکاً پیشبینی کند. ورود متغیرهای مستقل در رگرسیون به روشهای متعددی صورت میگیرد. روش همزمان، روش گام به گام و روش سلسلهمراتبی سه روش اساسی در این تکنیک است.
پیش فرضهای آزمون رگرسیون
آزمون تصادفی بودن دادهها: باید مشخص شود که ترتیب دادهها الگوی سیستماتیک ندارد و خطاها بهطور تصادفی توزیع شدهاند. نبودِ تصادفیّت میتواند نشان دهد که روند، چرخه یا الگوی زمانی در دادهها وجود دارد و برآورد ضرایب را مخدوش میکند.
آزمون نرمال بودن دادهها: در رگرسیون، نرمالبودن باقیماندهها اهمیت دارد، نه لزوماً نرمال بودن خود متغیرها. اگر توزیع خطاها نرمال باشد، اعتبار آزمونهای t و F افزایش مییابد و استنباط آماری دقیقتر انجام میشود.
آزمون دوربین–واتسون: این آزمون (Durbin–Watson) برای بررسی وجود خودهمبستگی خطاها بهویژه در دادههای سریزمانی بهکار میرود. مقدار آن نزدیک ۲ نشاندهندهٔ نبود خودهمبستگی و مقادیر بسیار پایین یا بالا بیانگر ارتباط خطاها با یکدیگر است.
آزمون همخطی: همخطی (Multicollinearity) بررسی میکند که آیا پیشبینها با یکدیگر بیش از حد همبسته هستند یا نه. همخطی بالا باعث ناپایداری ضرایب، کاهش دقت مدل و سختی تفسیر اثرات میشود. شاخصهایی مانند VIF و Tolerance برای تشخیص آن استفاده میشوند.
تحلیل رگرسیون با SPSS
این آموزش برای رگرسیون خطی ساده است برای مطالعه بیشتر به رگرسیون چندگانه رجوع کنید.
از منوی Analyze گزینه Regression فرمان Linear را اجرا کنید.
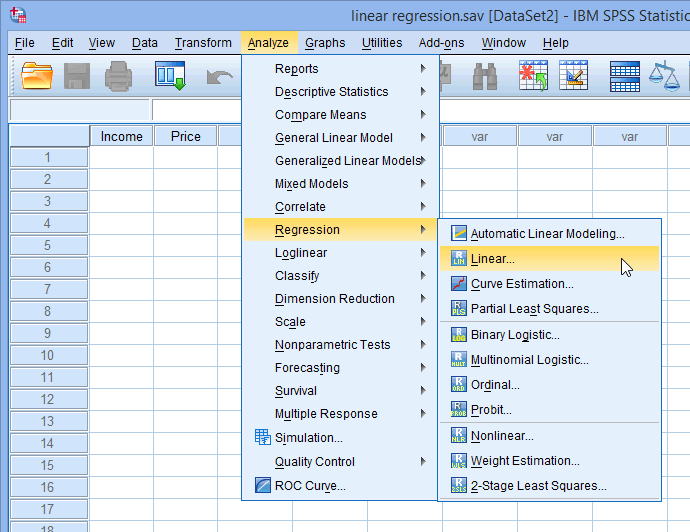
تحلیل رگرسیون در SPSS
متغیر وابسته تعهد را به کادر Dependent وارد کنید. در تکنیک رگرسیون خطی فقط میتوان یک متغیر را به کادر Dependent وارد کنید.
متغیر یا متغیرهای مستقل را به کادر Independent وارد کنید.
با تایید این کار چندین جدول در خروجی ظاهر خواهد شد.
برای مشاهده ضریب تعیین از جدول Model Summary استفاده کنید.
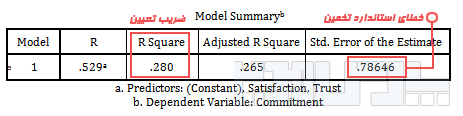
ضریب تعیین رگرسیون در SPSS
براساس نتایح این جدول متغیرهای پیش بین توانستهاند ۲۸% از تغییرات در متغیر وابسته را تبیین کنند.
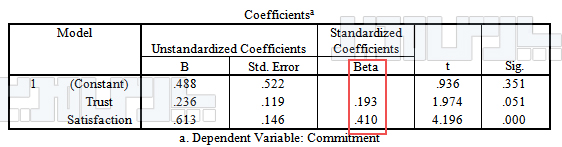
ضریب بتای رگرسیون در SPSS
میزان تاثیر براساس جدول نهایی و ضریب بتای استاندارد سنجیده میشود. براساس جدول فوق مشخص است میزان تاثیر متغیر اعتماد بر متغیر وابسته تعهد ۰/۱۹۳ است. آماره تی نیز ۱/۹۷۴ بدست آمده است ولی چون معنی داری از سطح خطا بزرگتر است بنابراین تاثیر اعتماد بر تعهد معنادار نیست. از سوی دیگر میزان تاثیر رضایت بر تعهد ۰/۴۱ بدست آمده است و آماره تی نیز ۴/۱۹۶ محاسبه شده است بنابراین رضایت بر تعهد تاثیر مثبت و معناداری دارد.
تحلیل رگرسیون در اکسل
نخست افزونه Analysis ToolPak را فعال کنید. برای این منظور آموزش فعال کردن افزونه Analysis ToolPak را مطالعه کنید. این افزوه در خود نرمافزار اکسل وجود دارد و نیازی به نصب برنامه خاصی ندارد.
از زبانه Data در بخش Analysis روی Data Analysis کلیک کنید.

گزینه Data Analysis در اکسل
در کادری که باز میشود گزینه Regression را انتخاب کنید.
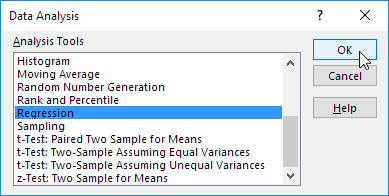
تحلیل Regression در اکسل
با کلیک روی فلش Y Range محدوده متغیر وابسته را انتخاب کنید.
با کلیک روی فلش X Range محدوده متغیر(های) مستقل را انتخاب کنید.
اگر مایل هستید مقادیر باقیمانده و خطا نیز گزارش شود تیک Residuals را فعال کنید.
برای مشاهده نمودار نرمال تیک Normal Probabilitis Plot را فعال کنید.
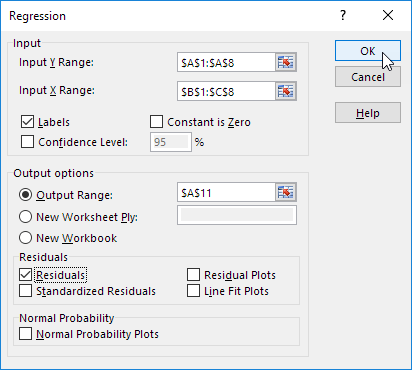
متغیرهای مستقل و وابسته رگرسیون
در پایان روی دکمه Ok کلیک کنید تا نتیجه مشاهده شود.
برای محاسبه شیب خط از تابع Slope (Y,X) استفاده کنید.
ضریب بتا، ضریب مسیر و اندازه اثر
ضریب بتا (Beta)
ضریب بتا معیاری استانداردشده در رگرسیون است که نشان میدهد هر متغیر پیشبین، با یک انحراف معیار تغییر، چه مقدار تغییر استاندارد در متغیر وابسته ایجاد میکند. این ضریب امکان مقایسهٔ اهمیت نسبی متغیرها را فراهم میسازد، چون همهٔ آنها به مقیاسی مشترک تبدیل شدهاند.
ضریب تعیین (R²)
ضریب تعیین شاخصی کلی برای بیان سهم مدل در توضیح واریانس متغیر وابسته است. مقدار آن بین صفر تا یک قرار میگیرد؛ مقادیر بالاتر نشاندهندهٔ قدرت بیشتر مدل در تبیین تغییرات هستند. R² نمیگوید کدام متغیر مؤثرتر است، بلکه کیفیت کلی مدل را منعکس میکند.
اندازه اثر (Effect Size)
اندازه اثر معیاری برای سنجش شدت واقعی اثر یک متغیر یا یک تفاوت است؛ نهفقط معناداری آماری. اندازه اثر کمک میکند بدانیم یک رابطه یا تفاوت، در عمل چقدر اهمیت دارد. در رگرسیون معمولاً از بتاهای استاندارد، f² یا تغییرات R² برای بیان اندازه اثر استفاده میشود.
حجم نمونه در رگرسیون
تعیین حجم نمونه در رگرسیون و تحلیل مسیر به تعداد متغیرهای پیشبین، اندازه اثر، و توان آماری بستگی دارد. در حالیکه فرمولهایی مانند کوکران و جدول مورگان برای برآورد حجم نمونهٔ کلی در پژوهشهای توصیفی کاربرد دارند، مدلهای پیشبینیمحور مانند رگرسیون و تحلیل مسیر نیازمند معیارهای تخصصیتری هستند.
یکی از رایجترین قواعد سرانگشتی، تخصیص ۱۰ تا ۱۵ آزمودنی به ازای هر متغیر پیشبین است؛ اما این قاعده سادهسازی است و دقت لازم برای مدلسازی تکمتغیره یا چندمتغیره را ندارد.
در حوزهٔ رگرسیون، پیشنهادهای گرین، تاباچنیک و فیدل (1991) بیشترین پذیرش را دارند. گرین دو معیار ارائه میکند:
- برای آزمون برازش کلی مدل: N ≥ 50 + 8k
- برای آزمون ضرایب منفرد: N ≥ 104 + k
که در این فرمول k تعداد متغیرهای پیشبین است. در عمل معمولاً مقدار بزرگتر بهعنوان حداقل حجم نمونه انتخاب میشود تا برآورد ضرایب پایاتر باشد.
این قواعد بهویژه در تحلیل مسیر اهمیت بیشتری پیدا میکنند، زیرا با افزایش مسیرها تعداد پارامترهای مدل رشد میکند و به نمونهٔ بیشتری نیاز است تا روابط مستقیم و غیرمستقیم بهدرستی برآورد شوند.
در مجموع، هرچه حجم نمونه بیشتر باشد، خطر برآوردهای کاذب و اثرات تصادفی کاهش مییابد و مدل توان تبیینی بهتری پیدا میکند. استفادهٔ همزمان از قواعد سرانگشتی و فرمولهای معتبر مانند گرین یا تاباچنیک و فیدل، راهحل مطمئنتری برای تعیین حجم نمونه در پژوهشهای مبتنی بر رگرسیون است.
رگرسیون غیرخطی
رگرسیون غیرخطی زمانی بهکار میرود که رابطه میان متغیر وابسته و پیشبینها با یک خط مستقیم قابل توصیف نباشد و الگو ماهیتی منحنیوار، نمایی، لجستیک، چندجملهای یا ترکیبی داشته باشد. در این رویکرد، بهجای برآورد یک شیب ثابت، تابعی انتخاب میشود که شکل واقعی دادهها را بهتر بیان کند و پارامترهای آن از طریق روشهایی مانند کمترین مربعات غیرخطی برآورد میشوند.
هطور کلی انواع توابع در رگرسیون غیرخطی به صورت زیر است:
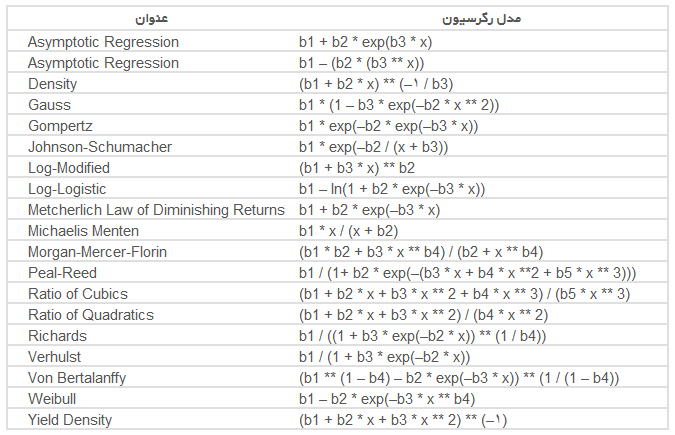
انواع رگرسیون غیرخطی
این نوع رگرسیون برای تحلیل پدیدههایی مناسب است که رفتارشان بهصورت شتابدار، اشباعشونده، چرخهای یا منحنی رشد ظاهر میشود؛ مانند منحنی یادگیری، رشد جمعیت، دوز–پاسخ در پزشکی، یا روابط پیچیده در علوم اجتماعی. رگرسیون غیرخطی انعطاف بیشتری نسبت به مدل خطی دارد، اما به اطلاعات کافی، حجم نمونه مناسب و انتخاب تابع درست نیازمند است. زیرا انتخاب نادرست شکل تابع میتواند به برازش ضعیف یا تفسیر نادرست منجر شود.
رگرسیون و تحلیل مسیر
رگرسیون نقطه آغاز تحلیل مسیر است؛ زیرا در تحلیل مسیر مجموعهای از معادلات رگرسیونی بهصورت همزمان برآورد میشود تا ساختار روابط مستقیم و غیرمستقیم میان متغیرها روشن شود. در رگرسیون تنها اثر مستقیم پیشبینها بر یک متغیر وابسته بررسی میشود، اما تحلیل مسیر این امکان را فراهم میکند که زنجیرهٔ اثرگذاری از یک متغیر به متغیرهای میانی و سپس به متغیر نهایی بهصورت نظاممند مدلسازی شود.
در این رویکرد، ضرایب استاندارد بتا بهعنوان مسیرهای علتومعلولی در نمودار مسیر تفسیر میشوند و پژوهشگر میتواند تشخیص دهد چه بخشی از اثر یک متغیر مستقیم و چه بخشی غیرمستقیم از طریق متغیرهای میانجی منتقل میشود. بهاینترتیب تحلیل مسیر گامی فراتر از رگرسیون است و تصویری ساختاریتر از روابط میان متغیرهای پژوهش ارائه میدهد.
تفاوت رگرسیون و همبستگی
همبستگی فقط شدت و جهت رابطه دو متغیر را میسنجد. ورود یا عدم ورود متغیرهای دیگر هیچ تغییری در مقدار همبستگی ایجاد نمیکند. رگرسیون اثر هر متغیر را بهصورت همزمان و در حضور سایر متغیرها بر متغیر وابسته برآورد میکند. بنابراین ورود متغیرهای جدید میتواند ضریب اثر متغیرهای قبلی را کم یا زیاد کند.
دانلود داده تفاوت رگرسیون و همبستگی
رابطه دو متغیر X و Y با استفاده از همبستگی پیرسون = ۰.۶۷۴
آزمون رگرسیون خطی را اجرا کنید: متغیر X را مستقل و Y را وابسته در نظر بگیرد. ضریب بتای رگرسیون = ۰.۶۷۴
در صورتیکه تنها دو متغیر X و Y وجود داشته باشند همیشه ضریب بتای استاندارد رگرسیون با ضریب همبستگی پیرسون برابر است.
رگرسیون و همبستگی
یکبار دیگر آزمون همسبتگی پیرسون را اجرا کنید و این بار متغیر Z را نیز وارد کنید؛ بازهم میزان همبستگی X و Y برابر ۰.۶۷۴ بدست خواهد آمد.
آزمون رگرسیون خطی را اجرا کنید و این بار متغیر X و Z را مستقل و Y را وابسته در نظر بگیرد. میزان تاثیر X بر Y برابر ۰.۲۹۵ بدست خواهد آمد.
در رویکرد رگرسیونی از آنجا که Z هم در نتایج Y موثر است بنابراین Y تنها تابعی از تغییرات X نیست. اگر متغیرهای بیشتری وارد مدل شود بازهم تغییرات Y نسبت به X از حساسیت کمتری برخوردار خواهد شد. دقت کنید جمیع تاثیرات متغیر Y از متغیرهای مستقل همیشه کوچکتر از ۱ است. اما در همبستگی این اصل رعایت نمی شود.
آیا همیشه اضافه شدن متغیرها باعث میشود ضریب بتای استاندارد تاثیر متغیر X بر متغیر Y کاهش یابد؟ خیر، اگر متغیری مانند Z وارد مدل شود و تاثیر منفی بر متغیر Y داشته باشد آنگاه تاثیر متغیر X بر متغیر Y افزایش پیدا میکند.
سخن پایانی
هدف روش رگرسیون (Regression) پیشبینی یک یا چند سازه وابسته یا ملاک براساس یک یا چند سازه مستقل یا پیشبین است. در این روش تاثیر همزمان متغیرهای پیشبین بر یک متغیر وابسته مورد بررسی قرار میگیرد. به دیگر سخن در این روش برخلاف روش همبستگی فقط به روابط دوبهدو توجه نمیشود و همه متغیرها باهم مورد تحلیل قرار میگیرند. از این روش برای تحلیل مسیر نیز استفاده میشود. با رشد روشهای آماری و پیدایش حداقل مربعات جزئی و مدلهای معادلات ساختاری، استفاده از رگرسیون کمتر گردید اما هنوز هم جایگاه مهمی در تحلیل آماری دارد.
منبع: حبیبی، آرش؛ سرآبادانی، مونا. (1401). آموزش کاربردی SPSS. تهران: ناروندانش.



