داده پرت (Outlier) در آمار کاربردی به داده یا دادههایی گفته میشود که مقدار آن بهصورت قابل اعتنایی با دیگر دادهها و مشاهدات متفاوت باشد. یکی از مهم ترین مفروضههای اجرای بسیاری از آزمونهای پارامتریک، نداشتن دادههای پرت است. برای همین شناسایی و تصمیمگیری پیرامون این دادهها بسیار اهمیت دارد. در این مقاله به آموزش روشهای شناسایی و حذف دادههای پرت خواهیم پرداخت.
تعریف داده پرت
داده پرت نقطهای است که با توزیع کلی داده سازگار نیست و بهاحتمال زیاد حاصل خطای ورود اطلاعات، ناهنجاری در فرایند، شرایط غیرعادی، یا گروهی از مشاهدات متفاوت است. البته نباید نباید دادههای پرت را با داده گمشده، اشتباهی و مقادیر ماتریس تکین اشتباه گرفت.
داده پرت یا دورافتاده به آن دسته از دادهها گفته میشود، که فاصله زیادی با دیگر دادههای تحقیق داشتهباشد. در اصل این نوع داده شامل مقادیری است که نسبت به میانگین کل دادهها فاصله زیادی دارد.
زمانی که پژوهشگر پرسشنامهای را در اختیار نمونه قرار میدهد همیشه ممکن است پاسخهای بسیار متفاوتی را دریافت کند. پاسخهایی که با دیدگاه دیگر پاسخگویان، بسیار بسیار متفاوت است. به این دادهها، دادههای پرت یا دور افتاده گفته میشود، که ممکن است نتایج آزمون را به کلی تغییر دهد.
مثال: در یک پژوهش تجربی، پرسشنامه در یک نمونه ۲۰۰ نفری از کاربران پارسمدیر، توزیع شد. براساس فایل داده، بازه سنی بیشتر کاربران ۲۵ الی ۴۵ سال بود ولی ۷ نفر از پاسخگویان با سن بیش از ۱۰۰ سال ثبت شدند. چنانچه میانگین سنی کاربران با وجود آن ۷ نفر برآورد شود، میانگین بسیار متفاوت خواهید شد. در اصل این هفت نفر به کلی آماره رنج سنی کاربران پایگاه پارسمدیر را تغییر میدهند. به این هفت کیس و میزان سن آنها داده پرت گفته میشود.
مشکلات داده پرت در پژوهش
وجود Outlier در تحلیل میتواند مشکلات بسیار جدی را برای تحلیل ایجاد کند. در ادامه به مشکلات ایجاد شده در تحلیل خواهیم پرداخت:
حساس بودن روشهای پارامتریک به دادههای پرت: عدم وجود دادههای دور افتاده برای بسیاری از آزمونهای آماری پارامتریک یک پیش فرض مهم است. برای اجرای این دسته از آزمونها باید دادههای پرت را حذف یا اصلاح نمایید. چرا که این دادهها میتواند روش اجرای پژوهش را زیر سوال ببرد.
ایجاد خطا در نتایج : دادههای دور افتاده میتواند نتایج بدست آمده را به کلی دچار اشکال کند.
تغییر شکل توزیع متغیرها: دادههای دور افتاده میتواند شکل توزیع نرمال را تغییر دهد. نرمال بودن توزیع یکی از پیش فرضهای بسیاری از تحلیلهای آماری است و دادههای پرت میتواند این توزیع را به هم بریزد.
دلایل ایجاد دادههای پرت
خطای ابزار، پژوهشگر و پاسخگو مهمترین دلایل ایجاد دادههای پرت هستند:
- اشتباه در طراحی مقیاس اندازه گیری (خطای اندازه گیری یا خطای ابزار)
- اشتباه در وارد کردن دادهها به نرم افزار (خطای پژوهشگر)
- اشتباه خود پاسخ دهنده به سوالات
خطای پژوهشگر زمانی رخ میدهد که برای مثال پاسخ آزمون شونده به سوال سن عدد ۲۵ بوده است، ولی خود محقق به اشتباه عدد ۲۵۰ را تایپ کرده است. گاهی نیز پاسخگو نمیخواهد به سوال پاسخ درست دهد. ممکن است پرسش حساسیت برانگیز بباشد. گاهی نیز پاسخگو بدون آنکه اصلا سوال را خوانده باشد و فقط جواب داده و رفته سوال بعدی یا این که سوال را اشتباه مطالعه کرده است.
روشهای تشخیص داده پرت
برای شناسایی دادههای پرت (Outlier Data) میتوان از دو دسته روش استفاده کرد، یکی از روشها ترسیم نمودارهای آماری است و روش دیگر استفاده از برخی از آزمونها و تفسیر آمارهها است.
- نمودار جعبهای
- نمودار میلهای
در ادامه به آموزش کامل این روشها خواهیم پرداخت.
شناسایی دادههای پرت با نمودار جعبهای
ترسیم نمودار جعبهای میتواند به ما کمک نماید که بفهمیم، آیا ما دادههای پرت داریم یا خیر؟ و این دادههای پرت مربوط به کدام یک از کیسهای تحقیق است؟ برای ترسیم این نمودار میتوان از چندین روش استفاده نمود :
روش اول: روی بخش Graphs بروید و سپس گزینه Chart Builder را بزنید. شناسایی دادههای پرت با نمودار جعبه ای
سپس در بخشی که باز میشود، باید از قسمت Gallery گزینه Boxplot را که مربوط به ترسیم نمودار جعبهای است را بکشید و به سمت قسمت بالا رها نمایید یا این که دو بار روی آن کلیک نمایید، تا شکل نمودار به کارد وسط انتقال یابد. سپس متغیرهای خود را که میخواهید نمودار جعبهای را برای آن ترسیم نمایید وارد تحلیل کنید.
روش دوم: از دستور Legacy Dialogs استفاده کنید و از بین گزینههای موجود در این بخش برای ترسیم نمودار (Chart) گزینه Boxplot را انتخاب کنید.

دو روش ترسیم نمودار جعبهای
همان طور که از تصویر مشخص است، داده هایی که از توزیع ما بسیار پرت هستند را در قالب یک سری شکل دایرهای در نمودار نشان میدهد. بالای هر کدام از این دایرهها عدد کیس مورد نظر را نیز نوشته است. میتوانید به کیسهای مشخص شده در نمودار مراجعه کنید و ببینید چرا جوابهای آنها پرت است؟ آزمون دهنده اشتباه کرده یا آزمون گیرنده؟
شناسایی دادههای پرت با نمودار میلهای
از طرفی میتوانید برای تکمیل کار خود نمودار میلهای را نیز ترسیم نمایید، که به سادگی نشان میدهد که آیا دادههای پرت دارید یا خیر؟
شناسایی دادههای پرت با نمودار Q-Q
روش دیگر شناسایی دادههای پرت، استفاده از نمودار چندک چندک است، که به ما نشان میدهد آیا متغیر ما دارای دادههای دور افتاده است یا خیر؟ برای ترسیم این نمودار گامهای زیر را بردارید:
از منوی Analyze به بخش Descriptive statistics بروید و گزینه Q-Q Plot را بزنید.
متغیر(های) مورد نظر را به کادر Variables وارد کنید.
در پایان تگمه OK را کلیک کنید تا خروجیها ارایه شود.
همچنین مقاله آموزش ترسیم نمودار چندک-چندک را نیز مطالعه کنید.
شناسایی دادههای پرت با نمره استاندارد (Z)
ابتدا باید بدانید که نمره استاندارد چیست؟ اگر بخواهید نمرات گروهها را با هم مقایسه کنید، باید باید آنها را به نمره استاندارد تبدیل کنید. چرا که هر کدام از این توزیعها میتواند میانگین متفاوتی داشته باشد. برای این کار و محاسبه نمره استاندارد (یا نمره Z)، باید مقادیر را از میانگین گروه کم کنیم و بر انحراف معیار تقسیم کنیم .
نمرات استاندارد میتواند مشخص کند، که کدام کیسهای ما داده دور افتاده دارد. برای اجرای این روش در نرم افزار spss میتوان از دو مسیر پیش رفت :
روش اول محاسبه نمره استاندارد: باید از منو Analyze گزینه Regression را بزنید. از بخش باز شده، گزینه Linear را انتخاب کنید.
بعد از آن که متغیرهای تحقیق را وارد تحلیل کردید، باید بر روی قسمت save بزنید.
در قسمت save، تیک گزینه standardized را فعال نمایید. سپس Continue را بزنید. در آخرین گام روی OK کلیک کنید.
روش دوم محاسبه نمره استاندارد : باید در بخش Analyze در منو Descritive Statistics گزینه Descritives را بزنید. سپس باید گزینه Save standardized values as variables را فعال کنید و در پایان بر روی Ok کلیک کنید.
پس از اجرای آزمون استاندارد، نمرات استاندارد تمامی کیسهای تحقیق در یک ستون محاسبه میشود. اگر مواردی در ستون باقی مانده استاندارد، بالای ۳ یا زیر ۳- باشد، باید آنها را حذف کرد، چون موارد دور افتاده حساب میشوند.
شناسایی دادههای پرت با فاصله ماهالانوبیس
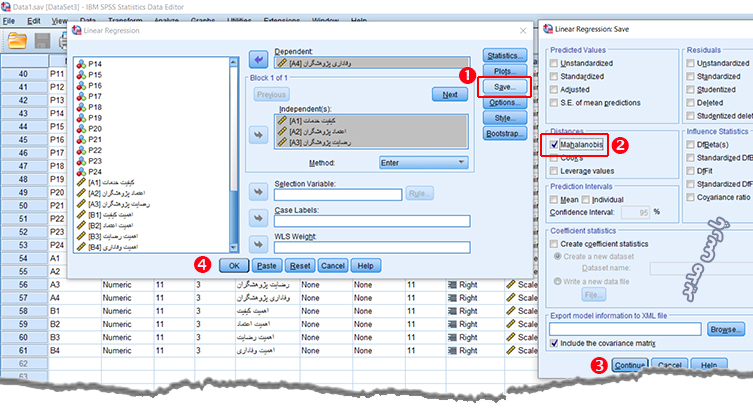
فاصله ماهالانوبیس روش دیگری برای شناسایی دادههای پرت است. این روش بیشتر بر روش رگرسیون استفاده میشود. نحوه محاسبه فاصله ماهالانوبیس در SPSS بدین شکل است که، ابتدا باید از منو Analyze گزینه Regression را بزنید. از بخش باز شده گزینه Linear را انتخاب کنید.
در گام بعدی متغیر وابسته و متغیرهای پیش بین را وارد تحلیل کنید. سپس وارد بخش Save شوید و تیک Mahalanobis را انتخاب کنید. در پایان گزینه ok را بزنید تا خروجیها نمایش داده شود.
شناسایی دادههای پرت با فاصله ماهالانوبیس
در خروجیهای نرم افزار باید فاصله ماهالانوبیس را پیدا کنید. از ماکسیموم این فاصله میتوانید مقدار بحرانی آن را مشخص نمایید.
بعد از دیدن مقدار ماکسیموم باید به جدول زیر مراجعه نمایید. بر اساس تعداد متغیرهای پیش بین تحلیل، مشخص شده که مقدار بحرانی ماهالانوبیس چند است. اگر عدد ماکسیموم خروجی، بزرگ تر از مقدار بحرانی بود، یعنی این که ما مقادیر پرت مشکل ساز داریم.
در گام پایانی باید به دادههای اصلی مراجعه نمایید. نرمافزار ستون تازهای بهنام MAH ایجاد کرده است. این مقادیر را از بزرگ به کوچک مرتب کنید و کیس هایی که مقدار ماهالانوبیس آنها بالا تر از مقدار بحرانی بوده را از تحلیل خود حذف نمایید.
روش تاباچنیک و فیدل
تاباچنیک و فیدل (Fidell & Tabachnic) روش دیگری برای تشخیص دادههای پرت پیشنهاد کردند. آنها از یک یا چند واحد (نه خیلی زیاد) بیشتر و کمتر از بزرگترین و کوچکترین مقادیر که در توزیع معمولی داده ها قرار دارند به جای مقادیر پرت بالاترین و پایین ترین استفاده کردند. برای نمونه دادههای زیر را درنظر بگیرید،
۲۴۵ ، ۲۴۰ ، ۲۳۸ ، ۱۶۲ ، ۱۶۱ ، ۱۶۱ ، ۱۶۱ ، ۱۵۸ ، ۱۵۷ ، ۱۵۷ ، ۱۵۵ ، ۱۵۵ ، ۱۵۱ ، ۵۰
مقادیر ۲۳۸، ۲۴۰، و ۲۴۵ از بالا و مقدار ۵۰ از پایین مقادیر پرت از توزیع داده ها می باشند. توسط روش تابچانیک و فیدل می توان از بالا مقدار ۲۳۸ را به ۱۶۳ ، مقدار ۲۴۰ را به ۱۶۴ و ۲۴۴ را به ۱۶۵ و از پایین مقدار ۵۰ را به ۱۵۰ تغییر داد تا این مقادیر نیز در مجموع کل توزیع داده ها قرار گیرند.
این روش کاملا قراردادی است به دیگر سخن در انجام چنین رفتارهایی با دادهها باید بصورت منطقی و حساب شده تصمیم گرفت.
ترسیم نمودار Scatterplot برای شناسایی دادههای پرت
روش دیگر این است که یک نمودار پراکندگی برای دو متغیر تحلیل ترسیم کنید. نکتهای که در مورد این نمودار باید رعایت شود این است که، دو متغیر تحلیل باید با مقیاس (Measure) فاصلهای (Scale) سنجیده شده باشد. وجود نقطه پراکنده در نمودار، نشان دهنده دادههای پرت است. برای ترسیم میتوانید از قسمت Graph گزینه Chart Builder را انتخاب کنید. سپس دکمه OK را بزنید. از قسمت Gallery گزینه Scatter/Dot را به کادر وسط بکشید و سپس متغیرهای تحلیل را در محورهای X و Y وارد کنید.
روش برخورد با دادههای پرت
به طور کلی بعد از آن که دادههای خود را جمع آوری کردید، باید از روش هایی برای شناسایی دادههای پرت استفاده کنید. بعد از این مرحله وارد تصمیمگیری در مورد دادههای پرت میشوید. دو راهکار اصلی برای برخورد با دادههای پرت وجود دارد:
در صورتی که امکان اصلاح دادهها وجود داشته باشد، میتوان از این روش استفاده نمود. باید بررسی کنید، چرا داده پرت ایجاد شده است؟ ممکن است در اثر اشتباه تایپی پژوهشگر باشد. برای بررسی این موضوع کافی است از روش زیر عمل نمایید:
در ابتدا در بخش Analyze در منو Descriptive Statistics گزینه Frequencies را بزنید. سپس متغیر مورد نظر را وارد تحلیل نمایید. سپس گزینه Statistics را بزنید. min و max را انتخاب کنید و در پایان OK را بزنید.
روش اصلاح داده پرت
در خروجیهای نرم افزار میتوانید مقدار ماکسیموم و مینیموم را مشاهده کنید. مثلا در نظر بگیرید که در وارد کردن دادهها ممکن است، خطا از جانب پژوهشگر باشد. به راحتی میتوانید بر اساس جدول خروجی ببنید که کدام یک از کیسها مقادیر پرت دارند. سپس به پرسشنامه مراجعه نمایید و اگر اشکالی در وارد کردن دادهها موجود بود میتوانید به راحتی اصلاح نمایید.
روش دیگری هم برای بررسی دادههای دور افتاده وجود دارد و آن این است که، در قسمت Frequencies میتوانید تیک Skewness را نیز بزنید تا چولگی را در جدول نشان بدهد. مقدار آن مشخص کننده وجود دادههای دور افتاده است.
روش حذف داده پرت
ممکن است دادههای پرت در گام پیشین قابل اصلاح نباشد. مثلا به کلی، خود آزمون شوندگان به اشتباه پاسخ دادهاند. در چنین حالتی باید این دادهها را در صورتی که تعداد آنها زیاد باشد، از تحلیل حذف کرد. در این بخش، روش حذف کیس هایی که در آن داده پرت موجود است را آموزش خواهید دید:
برای این آزمون باید به بخش Analyze بروید.
در گام بعدی وارد بخش Descriptive Statistics شوید و گزینه Explore را انتخاب کنید.
پس از وارد کردن دادههای تحلیل باید در قسمت Statistics گزینه Outilers را فعال نمایید. سپس ok را بزنید.
در خروجیهای نرم افزار میتوانید لیستی از دادههای دور افتاده تحلیل را به همراه شماره کیس آن مشاهده نمایید. این لیست پژوهشگر را برای حذف این مقادیر از تحلیل کمک میکند.
سخن پایانی
در آمار کاربردی مدیریت، نقاط پرت به مقادیری گفته میشود که بهطور محسوس از الگوی کلی دادهها فاصله دارند و همین ویژگی آنها را به یکی از مهمترین تهدیدها برای تحلیلهای مدیریتی تبدیل میکند. این مقادیر غیرعادی میتوانند شاخصها را منحرف کنند، نتایج رگرسیون را دچار خطا نمایند، و حتی باعث شوند آزمونهای آماری الگوهای واقعی را پنهان کنند. شناسایی دادههای پرت نیازمند ترکیبی از دانش مدیریتی، شناخت فرایند جمعآوری دادهها و روشهای آماری است؛ از جمله مرتبسازی دادهها، ترسیم نمودارهایی مانند باکسپلات، هیستوگرام و پراکنش، که بهروشنی مقادیر نامعمول را آشکار میکنند. در نهایت، تشخیص و مدیریت صحیح نقاط پرت نهتنها دقت تحلیلهای آماری را افزایش میدهد، بلکه به مدیران کمک میکند تصویر واقعیتری از رفتار فرایندها، کارکنان و مشتریان بهدست آورند.
منبع: حبیبی، آرش؛ سرآبادانی، مونا. (۱۴۰۱). آموزش کاربردی SPSS. تهران: ناروندانش.