دادههای گمشده

دادههای گمشده (Missing data) شامل خانههایی در یک یک فایل داده است که مقدار یا ارزشی برای متغیر مورد بررسی برای آن منظور نشده است. این مساله میتواند ناشی از پاسخ ندادن پاسخگویان باشد یا در وارد کردن دادهها اشتباه شده باشد.
نباید دادههای گمشده را با دادههای اشتباه و دادههای پرت اشتباه کرد. این مشکل زمانی روی میدهد که یک پاسخگو عمدی یا غیرعمدی به یک یا چند پرسش، پاسخ ندهد. در مجموع بیشتر زمانها این مشکل همراه با مطالعات علوم اجتماعی است زیرا در بسیاری از پروژهها، دادهها بوسیله پیمایش گردآوری میشوند.
زمانی که تعداد دادههای گمشده در یک پرسشنامه بیش از ۱۵% باشد مشاهده معمولاً از دادهها حذف میشود. البته یک مشاهده ممکن است از دادهها حذف شود حتی اگر تمام دادههای گمشده در پرسشنامه از ۱۵% بیشتر نشود. برای نمونه اگر بخش زیادی از پاسخها برای برآورد یک سازه، گمشده باشند ممکن است تمام مشاهده حذف شود. وجود تعداد زیادی داده گمشده برای یک سازه احتمالا به این دلیل روی میدهد که سازه پیرامون موضوعات حساسیتبرانگیزی باشد.
استفاده روبهرشد از روشهای گردآوری داده آنلاین میزان گمشدگی دادهها را کاهش میدهد. چرا که اگر به یک پرسش ویژه پاسخ داده نشود ممکن است مانع پاسخگویی به دیگر پرسشها شود. این رویکرد اجبار-پاسخ برخی افراد را تحریک میکند تا شرکت در پیمایش را متوقف کنند. با این وجود بیشتر زمانها اینگونه نیست. یعنی پاسخدهندگان به پرسش، پاسخ میدهند و گزینهها را پر می کنند. دلیل پرش از روی یک پرسش بیتوجهی است. نظر به اهمیت موضوع در این آموزش شیوه برخورد با دادههای گمشده تشریح شده است.
شناسایی دادههای گمشده در SPSS
شناسایی دادههای گمشده در نرمافزار SPSS با استفاده از دستور Replace Missing Values از منوی Transform قابل انجام است.
پس از انتخاب کادری مانند زیر نمایان خواهد شد:
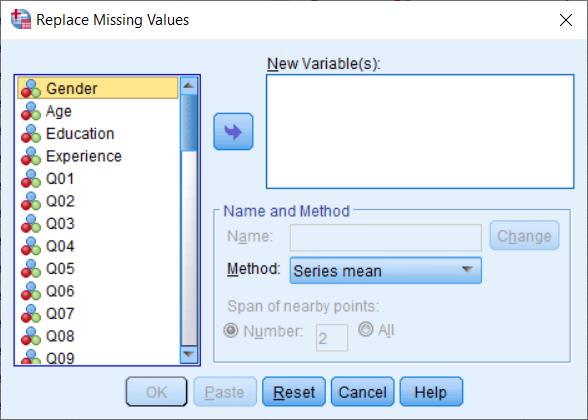
شناسایی دادههای گمشده در SPSS
تمامی متغیرهای مورد نظر خود را به کادر New Variables منتقل کنید.
پیش از این کار از کشوئی Method نوع پوشش نقاط خالی و فاقد داده را انتخاب کنید. موارد زیر در دسترس است:
- گزینه series mean: پرکردن جاهای خالی براساس میانگین دادههای آن فیلد پر میکند.
- گزینه Mean of nearby points: جای خالی را براساس میانگین دادههای اطراف آن خانه خالی پر میکند.
- گزینه Median of nearby points: جای خالی را براساس میانه دادههای اطراف آن خانه خالی پر میکند.
- گزینه Linear interpolation: جاهای خالی را براساس معادلات خطی دادهها پر میکند.
- گزینه Linear trend at point: جاهای خالی را براساس روندنمای خطی دادهها پر میکند.
پیشنهاد میشود برای ستونهای مربوط به متغیرهای طیف لیکرت از گزینه series mean و برای اطلاعات آمار توصیفی و دادههای اسمی و ترتیبی از گزینه Median of nearby points استفاده کنید.
چند نکته کلیدی
استفاده از گزینه Replace Missing Values نکات مربوط به خود را دارد. برای نمونه فرض کنید متغیری مانند Q1 را برای اسکن دادههای گمشده انتخاب کرده باشید در این صورت خود برنامه متغیری با نامی مانند Q1_1 درست میکند. پس از اسکن دادههای گمشده و تکمیل آن براساس پوشش نقاط خالی که انتخاب کردهاید یک فیلد جدید با نام Q1_1 در انتهای فایل داده قبلی ایجاد و نتایج را ذخیره میکند.
اگر میخواهید چنین نشود و اصلاحات در همان فیلد قبلی صورت گیرد (و معمولاً هم چنین است) خودتان نام متغیر را به همان نام قبلی تغییر دهید و دکمه را که اکنون فعال شده است را فشار دهید.
اگر از کشوئی Method یکی از دو گزینه زیر را انتخاب کنید باید در قسمت Number مشخص کنید منظورتان از Nearby (همان دادههای اطراف) چند داده است. همانطور که بیان شد گزینه Mean of nearby points جای خالی را براساس میانگین دادههای اطراف آن خانه خالی پر میکند. گزینه Median of nearby points نیز جای خالی را براساس میانه دادههای اطراف آن خانه خالی پر میکند.
دادههای گمشده در حداقل مربعات جزئی
دادههای گمشده در نرمافزار Smart PLS با نام «ارزشهای گمشده» یا Missing values نمایش داده میشود. اگر فایل دادهای که فراخوانی شده است دارای مقادیر گمشده باشد در زمانی که الگوریتم حداقل مربعات جزئی اجرا میشود یک زبانه جدید به نام ارزشهای گمشده به آن اضافه میشود.
راهکارهای مواجهه با دادههای گمشده در حداقل مربعات جزئی عبارتند از:
- جانهی میانگین [Mean replacement]
- حذف موردی [Casewise Deletion]
- حذف زوجی [Pairwise Deletion]
جانهی (Imputation) در آمار، فرایند جایگزینکردن دادههای گمشده با مقدارهای جایگزین است. جایگزین کردن یک نقطه داده گمشده، بهعنوان «جانهی یکه»، و یک مولفه یک نقطه داده بهعنوان «جانهی موردی» شناخته میشود.
در روش جانهی میانگین، از میانگین سایر دادههای مربوط به آن گویه در فایل داده به جای داده گمشده استفاده میشود. بهدیگر سخن مقادیر خالی هر ستون با میانگین سایر دادههای آن ستون جایگزین میشود. مزیت این روش آن است که حجم نمونه و میانگین دادههای هر ستون ثابت باقی میماند. با این وجود واریانس دادهها تغییر میکند و بر همین اساس ضریب مسیر سازهها نیز تغییر خواهد کرد.
حذف موردی (Casewise Deletion) راهکار دیگری است که نرمافزار Smart PLS برای حذف دادههای گمشده در هر معرف مورد استفاده در مدل را پیشنهاد میدهد. زمانیکه از این روش استفاده میشود دو موضوع نیاز به توجه بیشتری دارند:
نخست اطمینان از اینکه بهصورت سیستماتیک گروه ویژهای از پاسخگویان حذف نشدهاند. برای نمونه پژوهشگران بازاریابی بهصورت متناوب مشاهده میکنند که پاسخدهندگان ثروتمند در پاسخ به پرسشهای پیرامون میزان درآمدشان سر باز میزنند. استفاده از حذف مورد به صورت سیستماتیک، این گروه از پاسخگویان را نادیده میگیرد و بنابراین احتمالا موجب اریبی در نتایج میشود.
دو دیگر آنکه استفاده از این روش میتواند بهصورتی چشمگیر تعداد مشاهدات در مجموعه دادهها را کاهش دهد. بنابراین کنترل دقیق تعداد مشاهدههای مورداستفاده در برآورد مدل نهایی هنگامیکه از این روش استفاده میشود بسیار مهم است.
سخن پایانی
رویههای پیچیده بیشتری برای برخورد با دادههای گمشده پیش از تحلیل دادهها با استفاده از نرمافزار حداقل مربعات جزئی میتواند مورد استفاده قرار گیرد. در میان بهترین رویکردهای مقابله با این مشکل، تعیین پروفایل جمعیتشناختی پاسخگویان دارای گمشدگی دادهها و سپس محاسبه میانگین برای هر زیر گروه نمونه است. برای نمونه اگر پاسخگوی دارای گمشدگی دادهها، یک مرد بین ۲۵ تا ۳۵ سال و سابقه خدمت ۱۵ سال است میانگین آن گروه در پرسشهای دارای گمشدگی برآورد شود. سپس مشخص شود آیا پرسش دارای داده گمشده مرتبط با سازهای با آیتمهای چندگانه است. اگر پاسخ مثبت است معدل پاسخها برای همه آیتمهای مرتبط با سازه محاسبه شود.
مرحله پایایی استفاده از میانگین زیرگروه و معدل پاسخگویان معرف سازه برای تصمیمگیری پیرامون اینکه چه مقداری برای دادههای گمشده جایگزین شود، میباشد. این رویکرد کاهش در تغییرپذیری پاسخگویان را کمینه میسازد. همچنین پژوهشگران را قادر میسازد بهصورت مشخص بدانند برای غلبه بر مشکل گمشدگی دادهها چه کاری انجام شده است. در پایان روشهای آماری پیچیده گوناگونی برای برخورد با دادههای گمشده به رویکردهای رگرسیونی یا الگوریتم حداکثر انتظار، اتکا میکنند. در مجموع در مورد برازندگی این روشها در زمینه حداقل مربعات جزئی دانش اندکی وجود دارد. بنابراین پیشنهاد میشود هنگام مواجهه با گمشدگی دادهها در تحلیلهای حداقل مربعات جزئی از روشهای مورداشاره استفاده شود.
فهرست منابع
حبیبی، آرش؛ سرآبادانی، مونا. (۱۴۰۱). آموزش کاربردی SPSS. تهران: نارون.
حبیبی، آرش؛ جلالنیا، راحله. (۱۴۰۱). کتاب حداقل مربعات جزئی. تهران: نارون.
نگارنده: پشتیبانی پارسمدیر | آمار کاربردی مدیریت | 30 خرداد 02





من قرار دادم که موضوع مهمی هست و گم کردم ،شماره ثبت را هم گم کردم و تاریخ را
آیا از طریق کد ملی که به ثبت رسید قابل پیدا کردن هست
لطفاً راهنمایی بفرمایید
۰۹۱۶۴۷۱۵۰۲۰