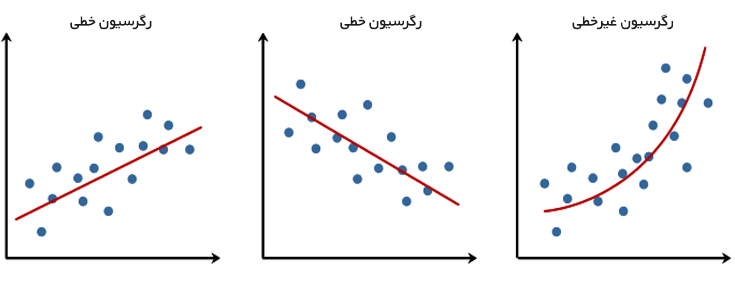
رگرسیون (Regression) یک روش آماری برای سنجش تاثیرات متغیرها با در نظر گرفتن روابط همزمان آنها بر یکدیگر است. معنای لغوی رگرسیون بازگشت به گذشته است و وجه تسمیه این روش نیز استفاده از دادههای گذشته برای پیشبنی آینده است.
شکلگیری و پیدایش روشهای رگرسیونی به دهه پایانی قرن نوزدهم برمیگردد. در سال ۱۸۸۶ کارل پیرسون توانست فرمولی برای محاسبه ضریب همبستگی ارائه دهد که علاوه بر نوآورانه بودن، مسیر جدیدی را در علم آمار فراهم کرد. این فرمول مبنای شکلگیری نظریه رگرسیون (Regression) بوده است. اگر که فرمول پیرسون، همبستگی بین دو متغیر را نشان میدهد در نظریه رگرسیون تغییرپذیری متغیر وابسته به دلیل تغییرپذیری متغیر مستقل نشان داده میشود.
تحلیل مسیر (Path analysis) یکی از روشهایی است که بر پایه مفهوم رگرسیون توسط سول رایت در اویل قرن بیستم معرفی شد. این روش کاربرد ضرایب بتای استاندارد رگرسیون چند متغیری در مدلهای ساختاری است. هدف تحلیل مسیر به دست آوردن برآوردهای کمی روابط علّی ( همکنشی یکجانبه یا کواریته) بین مجموعهای از متغیرهاست. ساختن یک مدل علّی لزوماً به معنای وجود روابط علّی در بین متغیرهای مدل نیست بلکه این علیت بر اساس مفروضات همبستگی و نظر و پیشینه تحقیق استوار است.
انواع روش رگرسیون (Regression)
انواع روشهای رگرسیونی براساس مفروضههای آماری و تعداد متغیرهای وابسته و مستقل قابل دستهبندی است. از نظر منطق زیربنایی آماری میتوان روشهای رگرسیونی خطی را به دو دسته تقسیمبندی کرد:
- رگرسیون خطی ساده (Simple linear regression)
- رگرسیون خطی تعمیمیافته (Generalized linear model)

انواع روش رگرسیون (Regression)
رگرسیون خطی ساده
این رویکرد مبتنی بر کمترین مربعات معمولی (OLS) است. همچنین از این روش برای پیشبینی «یک» متغیر وابسته براساس «یک» یا «چند» متغیر مستقل استفاده میشود. نقطه ضعف این رویکرد عدم امکان استفاده از آن برای پیشبینی همزمان چند متغیر وابسته است.
رگرسیون خطی تعمیمیافته
میتوان از مدل خطی عمومی یا Generalized Linear Model (GLM) برای تحلیل رگرسیونی استفاده کرد. GLM به محققان و تحلیلگران کمک میکند تا روابط پیچیده بین متغیرهای مستقل و وابسته را با دقت بیشتری مدلسازی کنند و پیشبینیهای دقیقی انجام دهند.
رگرسیون چندگانه (Multiple): پیشبینی یک یا چند متغیر وابسته براساس چند متغیر مستقل
رگـرسیون چندگانه تک عاملی (Univariate Multiple Regression) : پیشبینی یک متغیر وابسته براساس چند متغیر مستقل
رگـرسیون چندگانه چند عاملی (Multivariate Multiple Regression): پیشبینی چند متغیر وابسته براساس چند متغیر مستقل
در پژوهشهای رگرسیون هدف پیشبینی یک یا چند متغیر وابسته (ملاک) براساس یک یا چند متغیر مستقل (پیشبین) است. در رگرسیون چندگانه هدف پیدا کردن متغیرهای پیشبینی است که تغییرات متغیر وابسته را چه به تنهائی و چه مشترکاً پیشبینی کند. ورود متغیرهای مستقل در رگرسیون به روشهای متعددی صورت میگیرد. روش همزمان، روش گام به گام و روش سلسلهمراتبی سه روش اساسی در این تکنیک است.
تحلیل رگرسیون با SPSS
این آموزش برای رگرسیون خطی ساده است برای مطالعه بیشتر به رگرسیون چندگانه رجوع کنید.
از منوی Analyze گزینه Regression فرمان Linear را اجرا کنید.
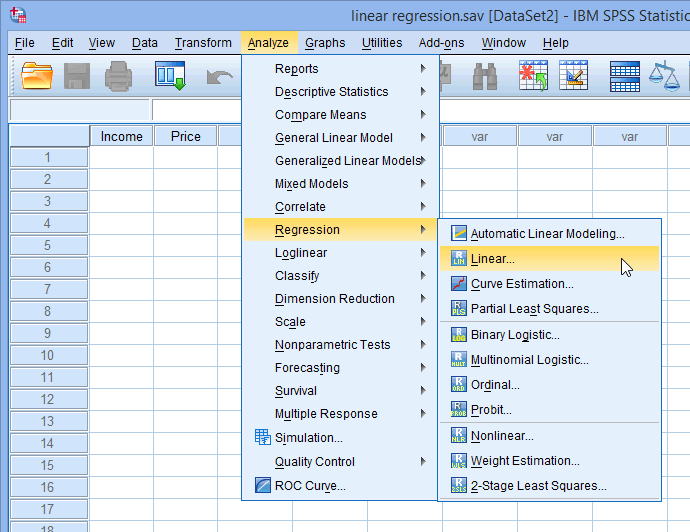
تحلیل رگرسیون در SPSS
متغیر وابسته تعهد را به کادر Dependent وارد کنید. در تکنیک رگرسیون خطی فقط میتوان یک متغیر را به کادر Dependent وارد کنید.
متغیر یا متغیرهای مستقل را به کادر Independent وارد کنید.
با تایید این کار چندین جدول در خروجی ظاهر خواهد شد.
برای مشاهده ضریب تعیین از جدول Model Summary استفاده کنید.
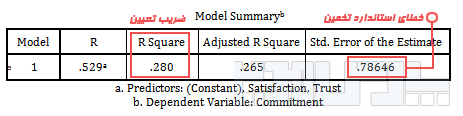
ضریب تعیین رگرسیون در SPSS
براساس نتایح این جدول متغیرهای پیش بین توانستهاند ۲۸% از تغییرات در متغیر وابسته را تبیین کنند.
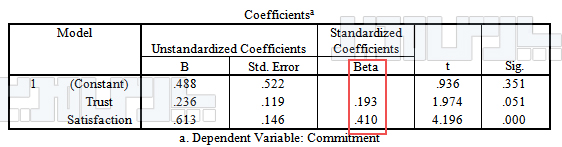
ضریب بتای رگرسیون در SPSS
میزان تاثیر براساس جدول نهایی و ضریب بتای استاندارد سنجیده میشود. براساس جدول فوق مشخص است میزان تاثیر متغیر اعتماد بر متغیر وابسته تعهد ۰/۱۹۳ است. آماره تی نیز ۱/۹۷۴ بدست آمده است ولی چون معنی داری از سطح خطا بزرگتر است بنابراین تاثیر اعتماد بر تعهد معنادار نیست. از سوی دیگر میزان تاثیر رضایت بر تعهد ۰/۴۱ بدست آمده است و آماره تی نیز ۴/۱۹۶ محاسبه شده است بنابراین رضایت بر تعهد تاثیر مثبت و معناداری دارد.
تحلیل رگرسیون در اکسل
نخست افزونه Analysis ToolPak را فعال کنید. برای این منظور آموزش فعال کردن افزونه Analysis ToolPak را مطالعه کنید. این افزوه در خود نرمافزار اکسل وجود دارد و نیازی به نصب برنامه خاصی ندارد.
از زبانه Data در بخش Analysis روی Data Analysis کلیک کنید.

گزینه Data Analysis در اکسل
در کادری که باز میشود گزینه Regression را انتخاب کنید.
تحلیل Regression در اکسل
با کلیک روی فلش Y Range محدوده متغیر وابسته را انتخاب کنید.
با کلیک روی فلش X Range محدوده متغیر(های) مستقل را انتخاب کنید.
اگر مایل هستید مقادیر باقیمانده و خطا نیز گزارش شود تیک Residuals را فعال کنید.
برای مشاهده نمودار نرمال تیک Normal Probabilitis Plot را فعال کنید.
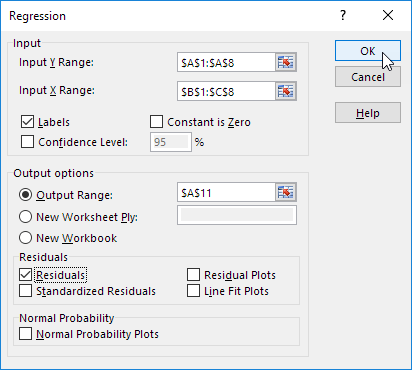
متغیرهای مستقل و وابسته رگرسیون
در پایان روی دکمه Ok کلیک کنید تا نتیجه مشاهده شود.
برای محاسبه شیب خط از تابع Slope (Y,X) استفاده کنید.
پیش فرضهای آزمون رگرسیون
برای انجام تحلیل رگرسیون باید از موارد زیر مطمئن شوید:
- حجم نمونه در رگرسیون
- آزمون صادفی بودن داده ها
- آزمون نرمال بودن داده ها
- آزمون دروبین-واتسون
- آزمون همخطی
برای مطالعه بیشتر بحث تفاوت رگرسیون و همبستگی را مطالعه کنید.
سخن پایانی
هدف روش رگرسیون (Regression) پیشبینی یک یا چند سازه وابسته یا ملاک براساس یک یا چند سازه مستقل یا پیشبین است. در این روش تاثیر همزمان متغیرهای پیشبین بر یک متغیر وابسته مورد بررسی قرار میگیرد. به دیگر سخن در این روش برخلاف روش همبستگی فقط به روابط دوبهدو توجه نمیشود و همه متغیرها باهم مورد تحلیل قرار میگیرند. از این روش برای تحلیل مسیر نیز استفاده میشود. با رشد روشهای آماری و پیدایش حداقل مربعات جزئی و مدلهای معادلات ساختاری، استفاده از رگرسیون کمتر گردید اما هنوز هم جایگاه مهمی در تحلیل آماری دارد.
منبع: حبیبی، آرش؛ سرآبادانی، مونا. (۱۴۰۱). آموزش کاربردی SPSS. تهران: نارون.