آزمون کولموگروف-اسمیرنوف (Kolmogorov-Smirnov) یک آزمون آماری ناپارامتریک است که برای بررسی توزیع دادهها استفاده میشود. به بیان آماری، آزمون کوموگروف-اسمیرنوف نوعی آزمون نیکوئی برازش برای مقایسه یک توزیع نظری با توزیع مشاهده شده است.
بیشتر پژوهشگران داخلی از آزمون کولموگروف-اسمیرنوف برای آزمون نرمال بودن دادهها استفاده میکنند. همچنین از این آزمون میتوان برای بررسی توزیع یکنواخت، نمایی و پواسون نیز استفاده کرد. با این وجود استفاده از این آزمون محدودیتهایی نیز به همراه دارد که پژوهشگران باید از آن آگاه باشند. نظر به اهمیت موضوع در ادامه به شیوه انجام آزمون با نرمافزار SPSS و پرسشهای پژوهشگران پرداخته میشود.
آزمون کولموگروف-اسمیرنوف برای پرسشنامه
آیا میتوان از آزمون کولموگروف-اسمیرنوف برای بررسی نرمال بودن دادههای پرسشنامه طیف لیکرت استفاده کرد؟
اجازه دهید پاسخ را ابتدا بدهم: خیر. دادههای طیف لیکرت در مقیاس ترتیبی تهیه میشوند. دادههایی که مقیاس اندازهگیری آنها ترتیبی باشد برای آزمون KS مناسب نیستند. همه مشاهدات در متغیرهای نمونهبرداری شده باید در هر مشاهده مستقل از مشاهده دیگر باشد. هر مشاهده فقط در یکی از مقولههای مرتب شده قرار گیرد. این شرایط در دادههایی که با طیف لیکرت اندازهگیری میشوند وجود ندارد. بنابراین نمیتوان از آزمون کولموگروف-اسمیرنوف برای بررسی نرمال بوده دادههای پرسشنامه طیف لیکرت استفاده کرد (فرجی، ۱۳۸۵ : ۲۱۸).
آیا حجم نمونه برای آزمون کولموگروف-اسمیرنوف محدودیتی دارد؟
حجم نمونه در آزمون KS محدودیتی ندارد و این آزمون برخلاف آزمون خی-دو با هر تعدادی از نمونه قابل انجام است. شرایط آزمون KS مانند شرایط آزمون تک متغیری خی-دو است. با این تفاوت که مقولههای متغیر مورد بررسی باید دارای ترتیب معینی باشند بطوریکه هر مشاهده ضمن استقلال از سایر مشاهدات باید تنها در یکی از مقولهها قرار گیرد (فرجی، ۱۳۸۵ : ۲۱۹).
برخلاف آنچه در برخی مقالهها به آن استناد میشود آزمون KS فقط برای دادههای کوچک (کمتر از ۳۰ تا) کاربرد ندارد. البته نتایج این آزمون برای دادههای کوچک طیف لیکرت معمولاً با نتایج چولگی و کشیدگی دادهها همراستا است. اما برای دادههای زیاد نتایج این آزمون با نتایج چولگی و کشیدگی و همینطور خط نرمال در نمودار هیستوگرام همخوانی ندارد.
آزمون کولموگروف-اسمیرنوف در SPSS
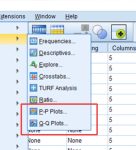
برای استفاده از آزمون کولموگروف-اسمیرنف مانند آزمون من-ویتنی فرمان زیر را اجرا کنید:
Analyze→ Nonparametric Tests →Leagcy Dialogs→۱-Sample K-S…
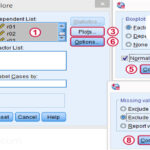
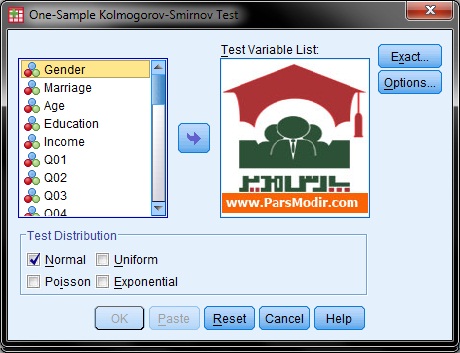
در کادر ظاهر شده گزینه Kolmogorov-smirnov را فعال کنید. یکی از مهمترین کاربردهای این آزمون سنجش نرمال بودن دادهها است که در فصل گذشته بیان شد. البته کاربردهای دیگری نیز وجود دارد که عبارتند از:
برای مقایسه توزیع مشاهده شده با توزیع نرمال گزینه Normal را فعال کنید.
جهت مقایسه توزیع مشاهده شده با توزیع یکنواخت گزینه Uniform را فعال کنید.
برای مقایسه توزیع مشاهده شده با توزیع پواسون گزینه Poisson را فعال کنید.
برای مقایسه توزیع مشاهده شده با توزیع نمائی گزینه Exponential را فعال کنید.
آزمون کولموگروف-اسمیرنوف
تفسیر آزمون کولموگروف-اسمیرنوف
هنگام بررسی یکنواخت بودن دادهها، فرض صفر مبتنی بر اینکه توزیع دادهها یکنواخت است را در سطح خطای ۰.۰۵ تست میشود. اگر مقدار معناداری بزرگتر یا مساوی سطح خطا (۵%) بدست آید، در این صورت دلیلی برای رد فرض صفر وجود نخواهد داشت. به عبارت دیگر توزیع دادهها یکنواخت خواهد بود.
هنگام بررسی نرمال بودن دادهها ما فرض صفر مبتنی بر اینکه توزیع دادهها نرمال است را در سطح خطای ۵% تست میکنیم. برای آزمون نرمالیته فرضهای آماری به صورت زیر تنظیم میشود:
H0 : توزیع دادههای مربوط به هر یک از متغیرها نرمال است
H1 : توزیع دادههای مربوط به هر یک از متغیرها نرمال نیست
بنابراین اگر آماره آزمون بزرگتر مساوی ۰.۰۵ بدست آید، در این صورت دلیلی برای رد فرض صفر وجود نخواهد داشت. به عبارت دیگر توزیع دادهها نرمال است.
سخن پایانی
آزمون کولموگروف-اسمیرنوف که به آزمون KS نیز موسوم است برای بررسی نرمال بودن دادهها استفاده میشود. شاید کولموگروف و اسمیرنوف خودشان هم تصور نمیکردند روزی این آزمون به چنین دردسر بزرگی برای دانشجویان ایرانی تبدیل شود. بزرگترین پرسش همه دانشجویان مدیریت و علوم اجتماعی آن است که آیا میتوان از این روش برای بررسی نرمال بودن دادههای پرسشنامه طیف لیکرت استفاده کرد؟ پاسخ منفی است زیرا طیف لیکرت یک مقیاس ترتیبی است. این آزمون برای دادههای اسمی و ترتیبی مناسب نیست. در واقع بیشتر برای دادههای نسبی و فاصلهای مناسب است. برای آگاهی بیشتر در این زمینه انواع مقیاس اندازهگیری متغیرها را مطالعه کنید.
یک پرسش کلیدی دیگر مقایسه این آزمون با روش پیشنهادی شاپیرو و ویلک است. هر دو آزمون با هدف بررسی نرمال بودن دادهها استفاده میشوند. در بیشتر موارد نیز نتایج هر دو آزمون مشابه هم بدست میآید ولی گاهی ممکن است تناقض در نتایج وجود داشته باشد. این اتفاق بدیهیو طبیعی است. به عنوان یک پژوهشگر هرگز از آزمونهای موازی که هدف یکسانی دارند استفاده نکنید. وظیف شما مقایسه و تشخیص برتری آزمونها نیست. یک روش را انتخاب کرده و براساس نتایج همان روش، پژوهش خود را ادامه دهید. در نهایت باید عنوان کرد اگر از پرسشنامهای با طیف لیکرت استفاده میکنید بهتر است از چولگی و کشیدگی دادهها برای بررسی نرمال بودن استفاده نمایید.
فهرست منابع
منبع: حبیبی، آرش؛ سرآبادانی، مونا. (۱۴۰۱). آموزش کاربردی SPSS. تهران: نارون.
فرجی، نصرالله. (۱۳۸۵). آمار توصیفی و استنباطی. تهران: پوران پژوهش.