آزمون تصادفی بودن دادهها
آزمون تصادفی بودن دادهها در SPSS یکی از شرایط زیربنایی جهت تعمیم نتایج نمونه به جامعه براساس اصل «تصادفی بودن دادهها» است. این موضوع با آزمون Run-Test در نرمافزار SPSS انجام میشود. با استفاده از آزمون Run مشخص میشود تا چه حد دنبالهای از اعداد به صورت تصادفی گردآوری شدهاند. برای نمونه در نمونهگیریهای تصادفی از مشتریان یک فروشگاه این آزمون بخوبی میتواند برای تایید ادعای تصادفی بودن دادهها مورد استفاده قرار گیرد. بیان فرضیههای آماری به صورت زیر است:
فرض صفر : توزیع دادهها به صورت تصادفی است.
فرض بدیل : توزیع دادهها به صورت تصادفی نیست.
اگر این آزمون در سطح خطای ۵% صورت گیرد چنانچه مقدار معناداری آزمون از سطح خطا بزرگتر باشد تصادفی بودن دادهها تایید میشود.
مسیر آزمون تصادفی بودن دادهها در SPSS
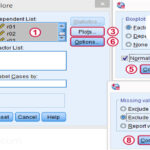
برای آزمون تصادفی بودن دادهها از منوی Analyze وارد مسیر زیر شوید
Analyze/Nonparametric Test/Runs…
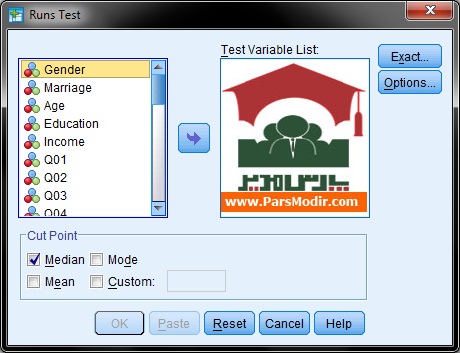
بررسی تصادفی بودن داده ها
میتوانید Cut Point را روی میانگین تنظیم کنید.
متغیرهای مورد نظر را هم میتوانید همزمان به کادر Test Variable List منتقل کنید.
ملاک تصمیمگیری Asymp. Sig. (2-tailed) میباشد. اگر این مقدار از سطح خطا بزرگتر باشد، دادهها تصادفی هستند. مطمئن باشید در این حالت آماره Z از ۱.۹۶ کوچکتر خواهد بود. همچنین پیشنهاد میشود آزمون نرمال بودن داده ها را مطالعه کنید.
خلاصه و جمعبندی
در بیشتر روشهای آماری که برمبنای «نمونهگیری» (Sample) شکل گرفتهاند، فرض بر تصادفی بودن نمونه و مشاهدات است. در نتیجه اطمینان از تصادفی بودن نمونهها از اهمیت زیادی برخوردار است. حتی در مباحث مربوط به رگرسیون نیز باید تصادفی بودن باقیماندهها مورد بررسی قرار گرفته تا صحت مدل ایجاد شده مورد تایید قرار گیرد. برای بررسی تصادفی بودن دادههایی که بخصوص در طی زمان جمعآوری شدهاند، میتوان از روشهای ترسیمی و رسم نمودارهای کنترلی به مانند مباحث کنترل کیفیت آماری نیز استفاده کرد. ولی در اینجا هدف استفاده از تکنیک آزمون فرض آماری است که بتواند با توجه به روند و توالی مشاهدات، تصادفی بودن آنها را تایید کند. استفاده از این روش کاربرد زیادی در تحلیل آماری مدیریت و علوم اجتماعی ندارد با این وجود آگاهی از آن نیز خالی از لطف نمیباشد.
منبع: حبیبی، آرش؛ سرآبادانی، مونا. (۱۴۰۱). آموزش کاربردی SPSS. تهران: نارون.
تهیه و تنظیم: پشتیبانی پارسمدیر
آمار کاربردی مدیریت | ۰۹ فروردین ۹۴



سلام ،وقتتون بخیر باشه،ممنونم از سایت خوبتون که مرجع خوبی برای نکات آماری هست،ممنون میشم اگرراهنمایی بفرمایید،آزمون من برای پرسشنامه ای است که میزان اهمیت تعدادی شاخص کارآفرینی سازمانی ست که میزان اهمیت شاخص ها براساس طیف لیکرت ۵تایی مشخص شده و بین ۲۲ نفر از خبرگان توزیع کردم ،سوالم این هست که برای فیلتر کردن و حذف شاخص های کم اهمیت ،براساس چه مولفه ی آماری ای بهتره که پیش برم؟،باتوجه به اینکه با نرم افزار spss، ابتداآزمون
کولموگروف اسمیرنف گرفتم وسپس آزمون Run test گرفتم،روش تحقیقم درست هست؟ ممنون میشم راهنمایی بفرمائید.
درود. پرسش شما ارتباطی به مطلب آزمون تی-تک نمونه ندارد. شما نیاز به مشاوره آماری دارید. اگر سوالی در مورد هر آزمونی داشتید زیر مطلب مربوط به همان آزمون مطرح کنید پاسخ داده میشود.