روش کریسپ (CRISP)
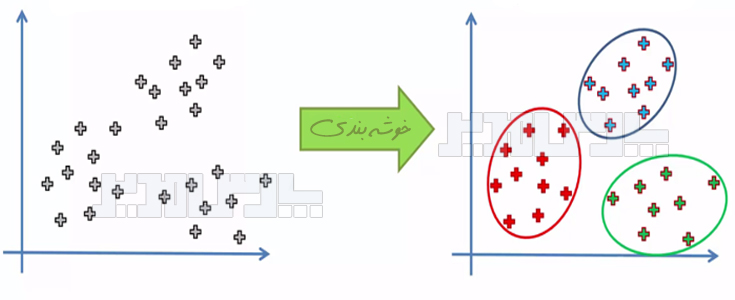
روش کریسپ (CRISP) الگوی فرایندمحور دادهکاوی است که راهکاری کاربردی و نظاممند برای خوشهبندی دادهها ارائه میکند. خوشهبندی را میتوان به عنوان مهمترین مسئله در یادگیری بدون نظارت در نظر گرفت. خوشهبندی با یافتن یک ساختار درون یک مجموعه از دادههای بدون برچسب درگیر است. خوشه Cluster به مجموعهای از دادهها گفته میشود که به هم شباهت داشته باشند.
کریسپ (CRISP) سرواژه عبارت Cross-industry standard process for data mining میباشد. در خوشهبندی سعی میشود تا دادهها به خوشههایی تقسیم شوند که شباهت بین دادههای درون هر خوشه حداکثر و شباهت بین دادههای درون خوشههای متفاوت حداقل شود. برای طبقهبندی هر داده به یک طبقه (کلاس) از پیشین مشخص شده تخصیص مییابد ولی در خوشهبندی هیچ اطلاعی از کلاسهای موجود درون دادهها وجود ندارد و به عبارتی خود خوشهها نیز از دادهها استخراج میشوند. خوشهبندی از مباحث اساسی در دادهکاوی است. در این مقاله کوشش شده است تا روش کریسپ به عنوان یک الگوی استاندارد دادهکاوی تشریح شود.
انواع روشهای خوشهبندی دادهها
روشهای خوشهبندی را میتوان از چندین جنبه تقسیمبندی کرد:
در روش خوشهبندی انحصاری پس از خوشهبندی هر داده دقیقأ به یک خوشه تعلق میگیرد مانند روش خوشهبندی کامینز K-Means. ولی در خوشهبندی با همپوشی پس از خوشهبندی به هر داده یک درجه تعلق بازاء هر خوشه نسبت داده میشود. به عبارتی یک داده میتواند با نسبتهای متفاوتی به چندین خوشه تعلق داشته باشد. نمونهای از آن خوشهبندی فازی است.
در روش خوشه بندی سلسلهمراتبی، به خوشههای نهایی بر اساس میزان عمومیت آنها ساختاری سلسله مراتبی نسبت داده میشود. مانند روش Single Link. ولی در خوشهبندی مسطح تمامی خوشههای نهایی دارای یک میزان عمومیت هستند مانند K-Means. به ساختار سلسلهمراتبی حاصل از روشهای خوشهبندی سلسلهمراتبی دندوگرام (Dendogram) گفته میشود. با توجه با اینکه روشهای خوشهبندی سلسلهمراتبی اطلاعات بیشتر و دقیقتری تولید میکنند برای تحلیل دادههای با جزئیات پیشنهاد میشوند ولی از طرفی چون پیچیدگی محاسباتی بالایی دارند برای مجموعه دادههای بزرگ روشهای خوشهبندی مسطح پیشنهاد میشوند.
روششناسی کریسپ (CRISP)
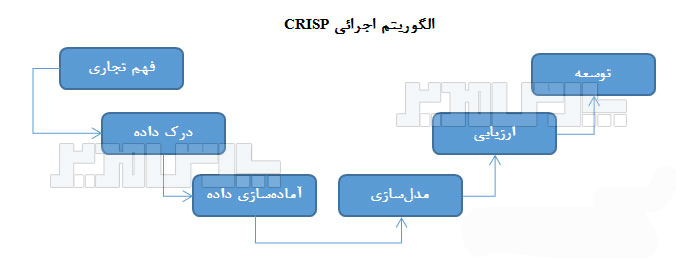
یکی از الگوهای خوشهبندی دادهها، روش کریسپ CRISP است که الگوریتم آن در زیر ارائه شده است:
الگوریتم اجرایی روش کریسپ CRISP
روش کریسپ CRISP مخفف CRoss Industry Standard Process for Data Mining فرایندهای استاندارد صنعت متقابل برای دادهکاوی است. در واقع روشهای تحلیل متفاوتی برای اجرای پروژههای دادهکاوی وجود دارد. روش تحلیل CRISP یا «فرایندهای استاندارد صنعت متقابل برای دادهکاوی» یکی از روشهای منطف و پرکاربرد در این زمینه است.
روشهای خوشهبندی نمیتوانند تمام نیاز یک مسئله را بهطور موازی و همزمان برطرف کنند. در دادههای بزرگ به دلیل وجود مشکل پیچیدگی زمانی، الگوریتم قابل اجرا برای هر دادهای نیست. همچنین در دادههایی که دارای ویژگیهای زیادی هستند امکان بروز نتایج با تفسیرهای مختلف وجود دارد.
گامهای روش کریسپ (CRISP)
کریسپ یک مدل فرایندی است که در شش گام برای سازماندهی کردن نتایج استفاده میکند.
فهم تجاری: این مرحله شامل گردآوری الزامات و مصاحبه با مدیران ارشد و خبرگان برای تعیین اهدافی بالاتر از کار با دادهها میشود.
درک داده: مرحله درک داده شامل نگاه نزدیکتر به دردسترس بودن داده برای دادهکاوی میشود. این مرحله شامل گردآوری دادههای اولیه، توصیف داده، کشف داده، و تغییر کیفیت داده میشود.
آماده سازی داده: آماده سازی داده یکی از مهم ترین و اغلب زمان برترین جوانب پروژههای دادهکاوی است و شامل انتخاب داده، پاک سازی داده، ساختاربندی داده جدید، و ادغام داده میشود.
مدل سازی: دادهای که زمان صرف کرده برای مهیا شدن , آماده است تا الگوریتمهای دادهکاوی را بیاورد، و نتایج شروع میکند به نشان دادن راه حل هایی برای مشکل تجاری مطرح شده. تکنیکهای انتخاب مدل سازی، ایجاد یک طراحی آزمون، ساختن مدلها، و ارزیابی مدل این مرحله را میسازد.
ارزیابی: در این مرحله، ارزیابی نتایج، فرایند بازبینی، و تعیین مراحل بعدی انجام شده است.
توسعه: توسعه فرایند استفاده از ادراکات جدید برای ایجاد بهبود در سازمان است.
محدودیتها و بحث
روش کریسپ CRISP فرآیند استاندارد صنعتی متقاطع برای دادهکاوی یا به صورت مصطلح کریسپ، یک مدل فرآیندی استاندارد باز است که رویکردهای عمومی متخصصان دادهکاوی را تشریح میکند، این روششناسی پرکاربردترین مدل تحلیلی میباشد. کریسپ یک مدل فرآیند دادهکاوی است که راهبردهای معمولی که توسط دادهکاوان خبره برای غلبه بر مشکلات دادهکاوی استفاده میشود را شرح میدهد. این متدولوژی در سال ۲۰۱۵ میلادی توسط شرکت آیبیام به نام روش متحد شده راهبردهای تحلیلی برای دادهکاوی یا آسوم ASUM تغییر نام داد.
متأسفانه چندین مسئاله در خصوص روشهای خوشهبندی مطرح است که هنوز به شکل کامل پاسخ داده نشدهاند. و همچنان تلاشهای بسیاری به منظور حل آنها انجام میگیرد. روشهای خوشهبندی قادر نیستند تمامی نیازهای مسائل را به طور همزمان برآوردهکنند. به دلیل پیچیدگی محاسباتی زیاد در برخورد با مجموعه دادههای بزرگ با تعداد داده زیاد و تعداد ویژگیهای زیاد برای هر داده عملی نیستند. به دلیل وابستگی شدید به تعریف معیار شباهت بین دادهها در مسائلی که تعریف معیار شباهت مشکل باشد نتایج مطلوبی تولید نمیکنند. در نهایت برای نتایج آنها میتوان تفسیرهای مختلفی بیان کرد.
منبع: حبیبی، آرش؛ سرآبادانی، مونا. (۱۴۰۱). آموزش کاربردی SPSS. تهران: نارون.
تهیه و تنظیم: پشتیبانی پارسمدیر
روش تحقیق | ۱۲ فروردین ۹۴





