توافق کدگذاری در تحلیل کیفی
توافق کدگذاری (Intercoder Agreement) یک روش سنجش پایایی تحقیقات کیفی است که براساس میزان تشابه کدگذاری انجام شده بوسیله چندگذار برآورد میشود. سنجش میزان این موافقت با نرمافزار مکسکیودا امکانپذیر است.
هنگام تخصیص کدها به دادههای کیفی، توصیه میشود معیارهای خاصی تعیین شود. برای نمونه پژوهشگر فرض میکند که کدگذاری دلخواه یا تصادفی نیست، بلکه به سطح معینی از قابلیت اطمینان رسیده است. تابع توافق نامه بین کدگذار MAXQDA امکان مقایسه دو نفر را که یک سند را مستقل از یکدیگر کدنویسی میکنند، میدهد. در تحقیقات کیفی، هدف از مقایسه کدگذارهای مستقل بحث در مورد تفاوتها، پی بردن به علت وقوع آنها و یادگیری از تفاوتها به منظور بهبود توافق کدگذاری در آینده است. به دیگر سخن، درصد واقعی توافق مهمترین جنبه ابزار نیست. با این حال، این درصد توسط MAXQDA ارائه شده است.
همیشه هدف تحلیلگران کیفی دستیابی به سطح بالاتری از توافق بین کدگذاران مستقل است. با این حال، بر رسیدن به یک ضریب استاندارد که از نظر آماری لازم است مانند تحقیقات کمی متمرکز نیست. در عوض، تمرکز بر بهبود عملی کیفیت کدگذاری است. به همین دلیل، روی ضریب یا درصد توافق (یعنی درصد تطبیق کدها) تمرکز نمیشود. بهجای آن پژوهشگران کیفی میخواهند تخصیصهای کدی را که سازگاری ندارند، بررسی و ویرایش کنند تا بتوانند با مطالب کدگذاری شده دقیقتری ادامه دهند.
رویه توافق کدگذاری در تحلیل کیفی
بررسی قرارداد بین کدگذار شامل موارد زیر است:
- دو کدگذار سند یکسان را به طور مستقل پردازش میکنند و آن را مطابق با تعاریف کد مورد توافق طرفین کدگذاری میکنند. این کار را میتوان بر روی یک رایانه یا در رایانههای جداگانه انجام داد. البته مهم این است که هر دو کدگذار نتوانند آنچه را که طرف مقابل کدگذاری کرده است ببینند.
- دو سند یکسان که توسط کدگذارهای مختلف کدگذاری شدهاند باید در پروژه MAXQDA یکسان باشند. اسناد باید یک نام داشته باشند، اما باید در گروههای اسناد مختلف باشند.
روش زیر توصیه میشود:
- اطمینان حاصل کنید که تمام اسنادی که قرار است توسط شخص دوم کدگذاری شوند به یک گروه اسناد اختصاص داده شدهاند.
- اسنادی را که قرار است توسط شخص دوم کدگذاری شود را فعال کنید.
- با استفاده از تابع Home > Project from Activated Documents یک کپی پروژه ایجاد کنید که فقط شامل اسناد فعال شده قبلی باشد.
- این کپی پروژه را به کدگذار دوم منتقل کنید.
- هر دو کدگذار نام خود را در پشت همه گروههای سند مینویسند.
- هر دو کدگذار به طور مستقل دادهها را کدگذاری میکنند و در صورت لزوم کدهای جدید اضافه میکنند (ممکن است توافق بر سر رنگ کد خاصی برای این کدهای جدید مفید باشد).
- از تابع Home > Merge Projects برای ادغام هر دو پروژه در یک پروژه استفاده کنید.
“سیستم اسناد” به شکل زیر خواهد بود:
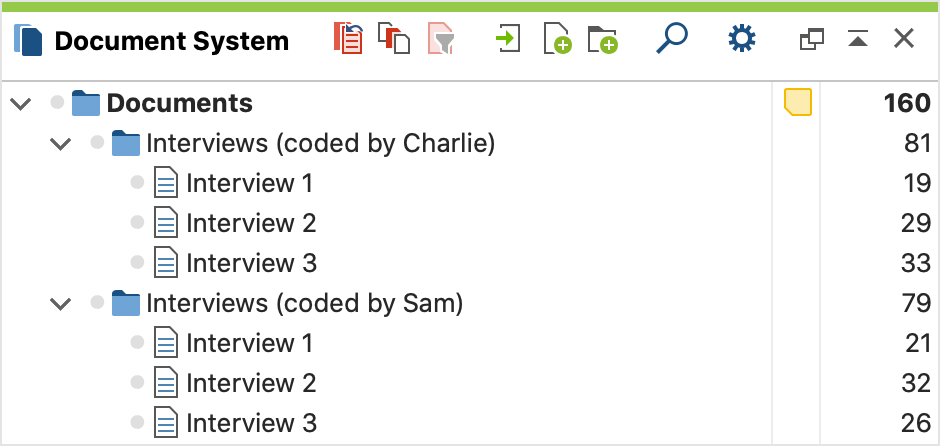
سیستم اسناد توافق کدگذاری
- اکنون تابع توافق نامه Intercoder MAXQDA میتواند برای مقایسه تخصیص کدها استفاده شود.
- پس از تکمیل مقایسه، این اسناد اضافه شده را میتوان حذف کرد.
لطفاً توجه داشته باشید: اگر اسناد کدگذاری شده توسط شخص ۱ در یک مجموعه اسناد و اسناد شخص ۲ در یک مجموعه اسناد دیگر (به جای گروههای اسناد) قرار داشته باشند، میتوان از عملکرد کدگذار MAXQDA نیز استفاده کرد. در این مورد نیز مدارک باید نام یکسانی داشته باشند و دو بار در پروژه گنجانده شوند.
باز کردن تابع قرارداد Intercoder
میتوانید این روش را از طریق Analysis > Intercoder Agreement شروع کنید تا بررسی کنید که آیا دو کدگذار در تخصیص کدهایشان موافق یا مخالف هستند.
از Analysis تابع توافق نامه بین کدگذار را شروع کنید.
کادر زیر ظاهر میشود که در آن میتوانید تنظیمات را برای بررسی قرارداد بین کدگذار تنظیم کنید.
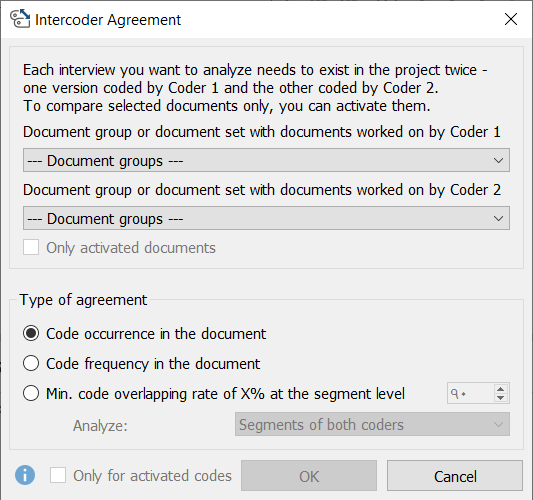
تنظیمات توافق کدگذاری
از منوی کشویی نخست کدگذاری مربوط به کدگذار شماره یک (Coder 1) را انتخاب کنید.
از منوی کشویی دو کدگذاری مربوط به کدگذار شماره دو (Coder 2) را انتخاب کنید.
سه نوع توافق قابل انتخاب است:
- توافق پیرامون کدهای شناساییشده
- توافق پیرامون تعداد کدها
- حداقل توافق پیرامون نرخ تقاطع
گزینه ۱ (سطح مقایسه سند): وقوع کد در سند
ملاک وقوع یا عدم وجود کد در سند است (یعنی: کد رخ میدهد در مقابل کد رخ نمی دهد). این گزینه میتواند مفید باشد، به عنوان مثال، اگر با اسناد نسبتا کوتاه، مانند پاسخهای متنی رایگان به نظرسنجی، و با تعداد زیادی کد کار میکنید.
گزینه ۲ (سطح مقایسه اسناد): فراوانی کد در سند
ملاک تعداد دفعات وقوع کد در سند است. به طور دقیق تر، تناوب تطبیق (توافق) تخصیص کد.
گزینه ۳ (سطح مقایسه بخش): حداقل. نرخ تقاطع کد X٪ در سطح بخش
سیستم بررسی میکند که آیا دو کدگذار «موافق هستند»، یعنی اینکه آیا در کدگذاری بخشهای جداگانه مطابقت دارند یا خیر. این گزینه پیشرفته ترین از این سه گزینه است و رایج ترین گزینه برای کدنویسی کیفی است. برای تعیین اینکه چه زمانی دو بخش کدگذاری شده مطابقت دارند، میتوان یک مقدار درصد تنظیم کرد.
تحلیل نتایج گزینه ۱ (Code occurs in the document)
نرمافزار MAXQDA دو جدول ایجاد میکند:
- جدول نتایج ویژه کد (Code-specific results table)
- جدول نتایج (Result table)
جدول نتایج ویژه خاص
«جدول نتایج ویژه کد» همه کدهای ارزیابی شده را فهرست میکند و نشان میدهد که کدگذارها با چه تعداد سندی در تخصیص کدشان مطابقت دارند:
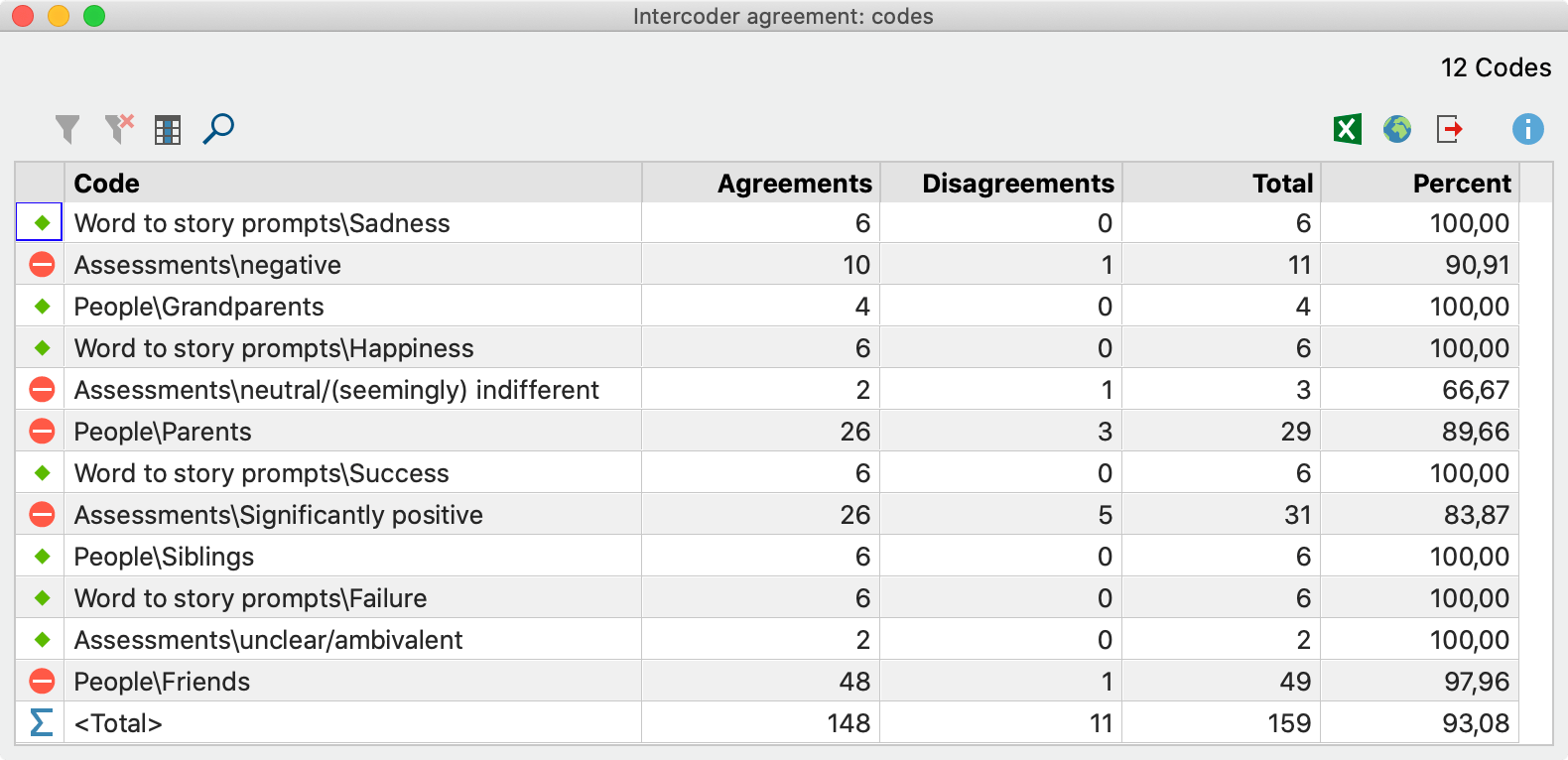
جدول نتایج ویژه کد
در جدول مثال بالا سمت راست نشان میدهد که در مجموع ۱۲ کد مورد تجزیه و تحلیل قرار گرفته است. اختلاف نظر (که با علامت توقف در ستون اول مشخص شده است) برای کد “ارزیابی ها/منفی” و کد “ارزیابی ها/خنثی…” و تنها در یک سند (که با ستون “بدون توافق” مشخص شده است) وجود داشت. اعداد در ستونهای توافقنامه، بدون توافق و کل به تعداد اسناد اشاره دارد.
ستون “درصد” نشان میدهد که میزان توافق درصد نسبت به کد مربوطه چقدر است. خط <Total> برای محاسبه میانگین درصد توافق استفاده میشود – در مثال، ۹۳.۳۳٪ است.
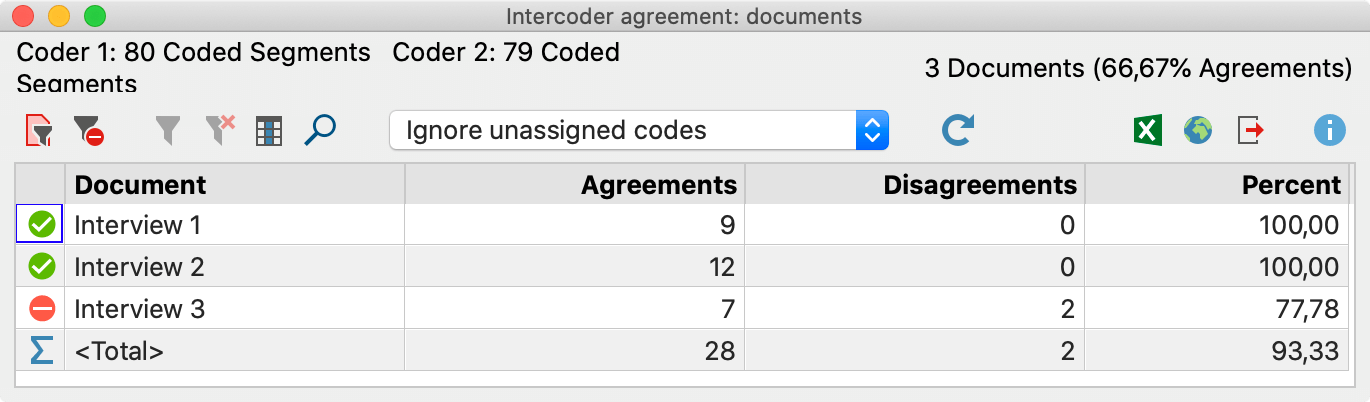
جدول نتایج دقیق
جدول نتیجه تمام اسناد ارزیابی شده را فهرست میکند و بنابراین اطلاعات دقیقی در مورد توافق اسناد جداگانه ارائه میدهد.
جدول نتایج دقیق
جدول دارای ساختار زیر است:
- اگر کدگذاران ۱ و ۲ همان کدها را به سند اختصاص داده باشند، ستون اول یک نماد سبز رنگ را نشان میدهد. در این مورد «اختلاف» وجود ندارد و درصد توافق ۱۰۰ درصد است.
- ستون “Agreement” تعداد تخصیص کدهایی را نشان میدهد که بین کد ۱ و کدگذار ۲ برای این سند مطابقت دارند.
- ستون “درصد” توافق درصد (یعنی تعداد نسبی تخصیص کدهای منطبق) را نشان میدهد. درصد توافق به شرح زیر محاسبه میشود: مسابقات / (مطابقات + غیر منطبق). برای مصاحبه ۳، مثال مقدار ۷ / (۷+۲) کد = ۷۷.۷۸٪ را نشان میدهد – این نسبت کدهایی است که در مصاحبه ۳ مطابقت دارند.
- ستون آخر یک مقدار کاپا را نشان میدهد که حاوی یک تصحیح تصادفی برای سطح توافق است (محاسبه: به زیر مراجعه کنید).
- خط آخر “<Total>” مطابقتها و عدم تطابقها را جمع میکند. عدد در ستون “درصد” با میانگین تعداد کدهای مطابقت مطابقت دارد، در مثال ۹۳.۳۳ درصد است.
سربرگ دارای اطلاعات بیشتر است:
- در سمت چپ میتوانید تعداد تخصیص کدهای انجامشده توسط دو کدگذار را ببینید، که اغلب میتواند نشانههای اولیه رفتار کدگذاری یکسان یا متفاوت را نشان دهد. در مثال، یک کدگذار ۱۲ بخش و دیگری ۱۴ کد گذاری کرده است.
- تعداد اسناد تجزیه و تحلیل شده و تعداد نسبی اسناد کدگذاری شده یکسان در سمت راست نشان داده شده است: در مثال، اینها ۲ مورد از ۳ سند هستند که مربوط به ۶۶.۶۷٪ است.
افزون بر توابع معمول MAXQDA برای باز کردن مجدد تابع و فیلتر کردن و صادر کردن نتایج، نوار ابزار شامل ابزارهای مهم زیر نیز میباشد:
فیلتر فقط اختلافات را نمایش دهید () : تمام ردیفهای منطبق را پنهان میکند و دسترسی سریع به اسنادی را که کدنویسها مطابقت ندارند فراهم میکند.
نادیده گرفتن کدهای تخصیص نیافته / شمارش کدهای تخصیص نشده به عنوان منطبق: در اینجا میتوانید تصمیم بگیرید که آیا کدهای داده شده که توسط هر دو کدگذار اختصاص داده نشده است، به عنوان منطبق در نظر گرفته شوند یا نادیده گرفته شوند. تفاوت را میتوان با استفاده از جدول زیر توضیح داد:
| کدگذار ۱ | کدگذار ۲ | توافق؟ | |
|---|---|---|---|
| کد A | × | × | بله، همیشه |
| کد B | × | نه، هرگز | |
| کد C | براساس گزینه انتخاب شده |
کد C در بررسی توافق نامه بین کدگذار گنجانده شده است اما نه توسط کد ۱ و نه توسط کدگذار ۲ در سند اختصاص داده شده است. در این صورت، اگر گزینه Ignore unassigned codes را انتخاب کنید، کد C نادیده گرفته میشود و تعداد نسبی تخصیص کدهای منطبق ۱ از ۲ = ۵۰٪ است. اگر گزینه دیگر انتخاب شود، مطابقت ۲ از ۳ = ۶۷٪ است، زیرا کد C در نظر گرفته شده است.
جدول نتایج تعاملی
جدول نتایج تعاملی است. با دوبار کلیک کردن روی یک ردیف، مرورگر Code Matrix برای سند مربوطه باز میشود:
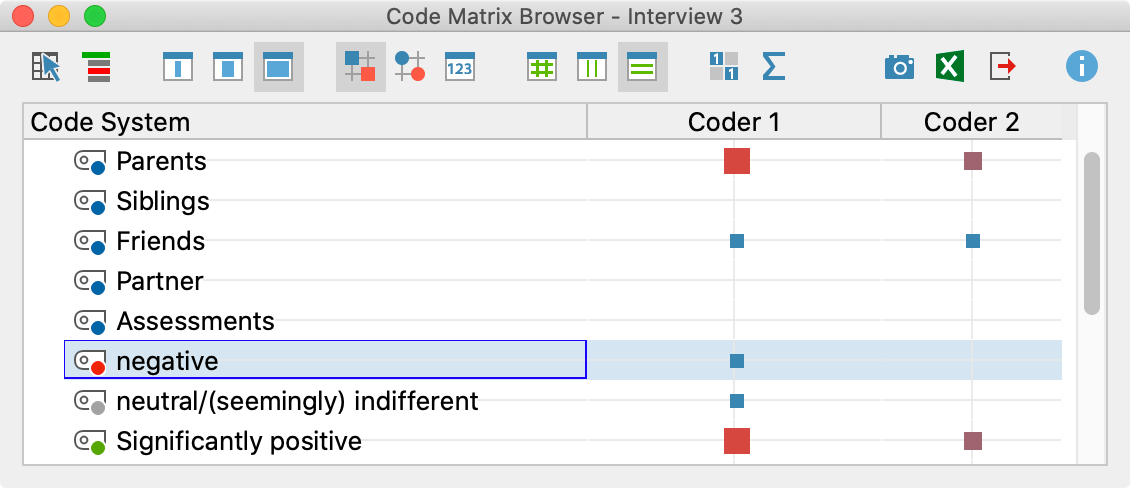
نتایج جدول تعاملی
نوار عنوان سند مقایسه شده را در مثال “مصاحبه ۳” نشان میدهد. نمای بلافاصله نشان میدهد که در کجای دو کدگذار اختلاف نظر وجود دارد: کدگذار ۱ کد “ارزیابی/منفی …” را اختصاص داده است، اما کدگذار ۲ این کار را نکرده است.
محاسبه کاپا (Rädiker & Kuckartz)
در ستون Kappa (RK) جدول نتایج یک مقدار تصحیح شده تصادفی برای توافق درصد را نشان میدهد. این احتمال را در نظر میگیرد که دو نفر به طور تصادفی کدهای مشابهی را در یک سند انتخاب و تخصیص دهند (اگر آنها به سادگی کدها را به طور تصادفی بدون در نظر گرفتن مواد داده انتخاب کرده باشند). این محاسبه تنها در صورتی معنا پیدا میکند که گزینه Count unassigned codes را به عنوان منطبق انتخاب کنید و بنابراین فقط در صورت انتخاب این گزینه قابل مشاهده است.
کاپا (Rädiker & Kuckartz) که به اختصار کاپا (RK) نامیده میشود، به صورت زیر محاسبه میشود:
Ac = توافق تصادفی = ۰.۵ به توان تعداد کدهای انتخاب شده برای تجزیه و تحلیل
Ao = توافق مشاهده شده = درصد توافق
Kappa (RK) = (Ao – Ac) / (1 – Ac)
تصحیح تصادفی به طور کلی بسیار کم است، زیرا احتمال تطابق تصادفی خیلی سریع با افزایش تعداد کدها ناچیز میشود.
تحلیل نتایج گزینه ۲ (Code frequency)
با این گزینه تجزیه و تحلیل، توافق زمانی اعمال میشود که دو کدگذار کدی با فرکانس یکسان در سند اختصاص داده باشند. تفاوت بین فرکانسها بی ربط است: اگر یک کدگذار یک کد A را یک بار و دیگری سه بار اختصاص دهد، یا اگر تفاوت یک بار در برابر شش بار باشد، هر دو موقعیت همیشه به عنوان یک اختلاف در نظر گرفته میشوند.
نتایج برای این گزینه تجزیه و تحلیل دوم، در اصل، با گزینه اول مطابقت دارد – با استثناهای زیر:
جدول نتایج خاص کد: تعداد اسنادی که فرکانس هر کد برای آنها ۱۰۰% مطابقت دارد در سلولها نمایش داده میشود.
جدول نتایج با اسناد تجزیه و تحلیل شده:
سلولها نشان میدهد که چه تعداد کد به طور یکسان توسط هر دو کدگذار در سند اختصاص داده شده است.
ستون “Kappa (RK)” هرگز نمایش داده نمیشود.
با دوبار کلیک کردن روی یک ردیف، مرورگر کد ماتریس نیز نمایش داده میشود.
در اینجا مربعهایی با اندازههای مختلف، تفاوتهای ویژگیهای کدگذاریشده سند کلیکشده را نشان میدهند.
تحلیل نتایج گزینه ۳ (Min code intersection rate)
با این گزینه، سیستم در سطح بخش بررسی میکند که آیا کدها مطابقت دارند یا خیر. اگر به عنوان مثال، کدر ۱ ۱۲ قطعه و کدر ۲ کد ۱۴ را داشته باشد، ۲۶ عملیات آزمایشی انجام میشود و جدول نتایج دقیق شامل ۲۶ ردیف است.
اغلب اوقات پیش میآید که کدنویسها هنگام تخصیص کدها کمی از یکدیگر منحرف میشوند، مثلاً به این دلیل که شخصی یک کلمه را بیشتر یا کمتر کدگذاری کرده است. این معمولاً از نظر محتوا نامربوط است، اما در صورت نیاز به کدگذاری کاملاً یکسان، میتواند منجر به تطابق بیدلیل درصد کمی شود و منجر به عدم توافق «کاذب» شود.
بنابراین میتوانید از قبل در کادر گفتگوی گزینهها مشخص کنید که چه زمانی دو تخصیص کد به عنوان یک تطابق در نظر گرفته میشوند. معیار مورد استفاده، درصد مساحت متقاطع دو تخصیص کد است. به سؤال زیر پاسخ داده میشود: مساحت متقاطع دو تخصیص کد نسبت به کل مساحت تحت پوشش دو تخصیص کد با بیرونی ترین مرزهای قطعه آنها چقدر است؟
ورودی به صورت درصد انجام میشود و مقدار آستانه را میتوان در کادر محاورهای تنظیم کرد. مقدار پیشفرض ۹۰ درصد است، اما میتوان آن را برای مقاصد آزمایشی بالاتر تنظیم کرد و در صورت وجود «آژارهای نادرست» بیش از حد، گام به گام کاهش داد.
در اینجا نیز دو جدول نتیجه تولید میشود: جدول نتایج مختص کد و جدول توافق تفصیلی.
جدول نتایج کد خاص
این جدول به اندازه تعداد کدهای موجود در بررسی توافق نامه بین کدگذار ردیف دارد. کدهایی که توسط هیچ یک از دو کدگذار اختصاص داده نشده اند نادیده گرفته میشوند. جدول یک نمای کلی از مطابقتها (توافق ها) و عدم تطابق (اختلافات) در تخصیص کد بین دو کدگذار ارائه میدهد. همچنین نشان میدهد که نقاط ضعف کجاست، یعنی برای کدام کدها توافق درصدی مورد نظر حاصل نشده است.
هر کد تعداد کل بخشهای کد شده (ستون کل)، تعداد مطابقتها (توافقها) و درصد توافق خاص کد را نشان میدهد. در ردیف <Total>، موارد (غیر) مطابق اضافه میشود تا بتوان میانگین درصد توافق را محاسبه کرد. در مثال، این ۹۳.۰۸٪ است.
جدول نتایج دقیق با بخشهای تجزیه و تحلیل شده
جدول دوم امکان بازرسی دقیق قرارداد بین کدگذار را فراهم میکند، یعنی میتوان تعیین کرد که دو کدگذار برای کدام بخش کدگذاری شده مطابقت ندارند. بسته به تنظیمات انتخاب شده، جدول شامل بخشهای هر دو کدگذار یا فقط بخشهای یک کدگذار است و نشان میدهد که آیا کدگذار دوم همان کد را در این مکان اختصاص داده است یا خیر.
توافق در انتساب یک کد به یک بخش معین با نماد سبز رنگ در ستون اول نشان داده میشود. یک نماد قرمز در این ستون نشان میدهد که هیچ توافقی (بدون مطابقت) برای این بخش وجود ندارد.
نکته: با کلیک بر روی سرصفحه ستون اول، ستون مرتب میشود تا تمام ردیفهای قرمز جدول در بالا فهرست شوند و بتوانید گام به گام هرگونه مغایرت را بررسی کرده و در مورد آن بحث کنید. با کلیک بر روی آیکون فیلتر () فقط قسمتهای مشکل دار نمایش داده میشوند.
تعامل جدول نتایج: بخشها را مقایسه کنید
جدول نتایج به صورت تعاملی با دادههای اصلی مرتبط است و امکان بازرسی هدفمند از بخشهای تجزیه و تحلیل شده را فراهم میکند:
- با کلیک بر روی یک ردیف، هر دو سند مرتبط در “سیستم اسناد” برجسته میشوند و آنها به طور پیش فرض در برگههای خود باز میشوند و بخش کلیک شده برجسته میشوند. در نوار ابزار میتوانید تنظیمات را از نمایش در دو تب به نمایش در دو مرورگر سند تغییر دهید – سپس سند کد شده توسط “Coder 2” در یک پنجره جداگانه نمایش داده میشود. این گزینه مخصوصاً اگر با دو صفحه کار میکنید مفید است.
- دوبار کلیک کردن بر روی مربع کوچک در ستونهای “Coder 1” یا “Coder 2” سند مربوطه را در “Document Browser” در محل بخش مورد نظر متمرکز میکند. این باعث میشود که بین دو سند به عقب و جلو بپرید و قضاوت کنید که کدام یک از دو کدگذار کد را مطابق دستورالعملهای تخصیص کد اعمال کردهاند.
- اگر روی یک ردیف با دکمه سمت راست ماوس کلیک کنید، یک منوی زمینه ظاهر میشود که در تصویر بالا نشان داده شده است که به شما امکان میدهد تخصیص کد را مستقیماً از یک سند به سند دیگر منتقل کنید. برای مثال گزینه Adopt the solution of Coder 1 را انتخاب کنید .
ضریب کاپا برای مطابقت دقیق مقولهها
در تحلیل کیفی، برآورد توافق بین کدگذارها، نخست به بهبود دستورالعملهای کدگذاری و کدهای فردی کمک میکند. با این وجود، اغلب مطلوب است که درصد توافق محاسبه شود. به ویژه با توجه به گزارش تحقیقی که بعداً تهیه میشود. این درصد توافق را میتوان در جدول نتایج ویژه کد بالا مشاهده کرد که در آن کدهای جداگانه و همچنین مجموعه همه کدها در نظر گرفته شده است.
بیشتر پژوهشگران تمایل دارند که نه تنها درصد سازگاری را در گزارشهای پژوهشی خود نشان دهند، بلکه ضرایب تصحیح شده را نیز لحاظ کنند. ایده اصلی چنین ضریبی کاهش درصد توافق به میزانی است که در تخصیص تصادفی کدها به بخشها به دست میآید.
در MAXQDA، ضریب توافق کاپا براساس دیدگاه Brennan و Prediger به سال ۱۹۸۱ قابل برآورد است. در جدول نتایج، روی نماد Kappa کلیک کنید تا محاسبه برای تحلیل در حال انجام شروع شود. نرمافزار MAXQDA جدول نتایج زیر را نمایش میدهد:

ضریب توافق کاپا (برنان و پردیگر، ۱۹۸۱)
تعداد کدهایی که مطابقت دارند در گوشه سمت چپ بالای جدول چهار قسمتی نمایش داده میشود. در گوشه بالا سمت راست و گوشه سمت چپ پایین، موارد غیر منطبق را خواهید دید، یعنی یک کد، اما نه کد دیگر، در یک سند اختصاص داده شده است. در MAXQDA، قرارداد بین کدگذار در سطح بخش، تنها بخش هایی را در نظر میگیرد که حداقل یک کد به آنها اختصاص داده شده است. بنابراین سلول در سمت راست پایین، طبق تعریف، برابر با صفر است (زیرا بخشهای سند تنها در صورتی در تحلیل گنجانده میشوند که توسط هر دو کدگذار کدگذاری شده باشند).
“P مشاهده شده” مطابق با درصد ساده توافق است، همانطور که در خط “<Total>” جدول نتایج مختص کد نمایش داده شد.
برای محاسبه «شانس P» یا شانس توافق، MAXQDA از یک پیشنهاد ارائه شده توسط برنان و پردیگر (۱۹۸۱) استفاده میکند که به طور گسترده با استفادههای بهینه از کاپا کوهن و مشکلات آن با توزیعهای مجموع لبههای نابرابر سروکار داشتند. در این محاسبه، تطابق تصادفی با تعداد دستههای مختلفی که توسط هر دو کدگذار استفاده شده است، تعیین میشود. این مربوط به تعداد کدهای جدول نتایج خاص کد است.
توجه داشته باشید: اگر کدنویسها تعداد یکسانی کد را به یک بخش اختصاص دادهاند و دو یا چند کد مورد تجزیه و تحلیل قرار گرفتهاند، باید مقدار کاپا فهرستشده در نتایج را در گزارش انتشار خود بگنجانید. اگر کدگذارها تعداد متفاوتی از کدها را به یک بخش اختصاص داده اند یا فقط یک کد آنالیز شده است، باید دومین مقدار کاپا فهرست شده در نتایج را درج کنید.
پیش نیازهای محاسبه ضرایب تصحیح شده تصادفی مانند کاپا
برای محاسبه ضرایبی مانند کاپا، معمولاً بخشها باید از قبل تعریف شوند و با کدهای از پیش تعیین شده ارائه شوند. با این حال، در تحقیقات کیفی، یک رویکرد رایج این است که بخشها را بهطور پیشینی تعریف نکنیم، بلکه وظیفهای را به هر دو کدگذار اختصاص دهیم تا همه نقاط سند را که مرتبط میدانند شناسایی کنند، و یک یا چند کد مناسب را اختصاص دهند. در این حالت، احتمال اینکه دو کدگذار یک بخش را با یک کد یکسان کدنویسی کنند کمتر خواهد بود و بنابراین کاپا بیشتر خواهد بود. همچنین میتوان استدلال کرد که احتمال تطابق کدگذاری تصادفی در متنی با چندین صفحه و کدهای متعدد آنقدر ناچیز است که کاپا با توافق درصد ساده مطابقت دارد. در هر صورت، محاسبه باید به دقت در نظر گرفته شود.
تهیه و تنظیم: پشتیبانی پارسمدیر
روش تحقیق | ۲۷ تیر ۰۲




ممنون از توضیحات جامع و کاربردی .به نظرم توضیحات شما بهتر از متخصصین مطالعات کیفی است
ارادتمندم. حالا چرا ما رو در زمره متخصصین مطالعات کیفی راه ندادید بزرگوارد؟ 🙂